

Всем привет. Сегодня я хочу рассказать про относительно новый продукт в стеке Apache Software Foundation для инженерии данных — OpenDAL.
Всем привет. Сегодня я хочу рассказать про относительно новый продукт в стеке Apache Software Foundation для инженерии данных — OpenDAL.

Привет, Хабр! С вами вновь Александр Бобряков, техлид в команде МТС Аналитики. И я с очередной статьёй из цикла про фреймворк Apache Flink.
В предыдущей части я рассказал, как тестировать stateless- и stateful-операторы Flink с использованием вспомогательных TestHarness-абстракций, предоставляемых Flink.
В этой статье напишем тесты на всю джобу с использованием мини-кластера Flink и при помощи JUnit Extension. Ещё мы начнём выделять удобные вспомогательные абстракции для тестов, которые понадобятся позже.

Airflow в Lamoda Tech играет роль оркестратора процессов обработки данных. Ежедневно с его помощью мы запускаем 1 800+ тасок на проде, примерно половина из которых являются Spark-приложениями.
Все Spark-приложения сабмитятся из Docker-контейнеров. И здесь сталкиваемся с проблемой: в нашем случае не существует готовых решений для запуска Spark-приложений, позволяющих легко править конфигурацию и следить за количеством потребляемых ресурсов.
Меня зовут Андрей Булгаков, я лид команды разработчиков Big Data в Lamoda Tech. Вместе с разработчиком Иваном Васенковым в этой статье мы поделимся историей создания Airflow-оператора для запуска Spark-приложений.

Сравниваем между собой качество 6 различных токенайзеров, включая новейший OpenAi Large|Small и E5 от Microsoft на задаче векторного поиска:
Ищем ответ на вопрос: В чем сила? в сборнике афоризмов и цитат.
Рассматриваются модели
text-embedding-ada-002
text-embedding-3-large
text-embedding-3-small
intfloat/multilingual-e5-large
ai-forever/ruBert-large
ai-forever/sbert_large_mt_nlu_ru
P.S. Бонусом сравнение как влияет токенайзер на качество задачи по классификации текста (30 классов).

Здесь будет рассказано о главных отличиях самого старого и базового алгоритма снижения размерности - PCA от его популярных современных коллег - UMAP и t-SNE. Предполагается, что читатель уже предварительно что-то слышал про эти алгоритмы, поэтому подробного объяснения каждого из них в отдельности приведено не будет. Вместо этого будут объяснены самые важные для практики свойства этих алгоритмов и то, на какие связанные с ними подводные камни можно налететь при неосторожности. Все особенности будут описаны на примерах, с минимумом теории; те пытливые умы, что почувствуют в процессе чтения жажду математической строгости, смогут удовлетворить её в литературе, ссылки на которую будут даны по ходу дела и в конце статьи.

В последнее время всё чаще и чаще натыкаюсь на термин data contract. И чтобы не отставать от трендов на рынке data engineering, решил изучить эту тему и рассмотреть тенденции. Постараемся понять, с чем его кушать и стоит ли кушать вовсе.

Управление ассортиментной матрицей и складскими запасами является нетривиальной задачей для бизнеса, требует аналитики и научного подхода к решению задачи. Одним из методов управления ассортиментом и закупками является ABC-XYZ классификация.
Рассмотрим ее реализацию на Python, поговорим об основных принципах построения и предобработке входных данных, в рамках рабочего проекта, в который мне пришлось погрузиться в одной крупной торгово-производственной компании.

Всем привет!
Как вы знаете, многие поставщики ПО ушли с российского рынка ввиду введённых санкций и многие компании столкнулись с необходимость заняться импортозамещением в кратчайшие сроки. Не стал исключением и наш заказчик. Целевой системой, на которое было принято решение мигрировать старое хранилище, стал Greenplum (далее GP) от компании Arenadata.
Этой статьей мы запускаем цикл материалов посвященных Greenplum. В рамках цикла мы разберем, как вообще устроен GP и как выглядит его архитектура. Постараемся выделить must have практики при работе с данным продуктом, а также обсудим, как можно спроектировать хранилище на GP, осуществлять мониторинг эффективности работы и многое другое. Данный цикл статей будет полезен как разработчикам БД, так и аналитикам.
Рассмотрим безобидную, на первый взгляд, ситуацию. Вы развернули новый кубернетес кластер, подключили сетку и стораджи, накатили мониторинги и квоты. Казалось бы, осталось нарезать неймспейсы и передать их в пользование коллегам в разработке. Однако, вы в курсе, что разработчики будут запускать команды через kubectl, а значит, по-хорошему, надо накинуть хотя бы "базовые" ограничения на их команды, ведь только так можно оградить себя от большинства проблем в процессе предстоящей эксплуатации кластера. ...Тем не менее, каким бы сложным действием ни казалась настройка кластера, если у вас есть некоторый запас времени, то милости прошу в краткое рассуждение о возможностях кубернетес контроллеров и практических способах применения Validating Admission Policy.
ИНСТРУКЪЦЫЯ ПО НАСТРОЙКЕ КУБЪ-КЛАСТЕРА
...
шаг 998 Подключите Validating Admission Policies
шаг 999 Отдайте, наконец, кластеръ в эксплуатацию
...

Многие компании в последнее время ввели должность «ИИ-тренера» (AI-тренера), при этом просто разметчики/ассесоры никуда не делись. Что это — просто красивая обертка нейминга над тем же самыми или что-то концептуально новое?
Давайте попробуем в этом разобраться и однозначно ответить на вопрос о различиях.

Привет, Хабр! Меня зовут Сергей Евсеев, сегодня я расскажу, как в Apache NiFi настраивается ETL-пайплайн на задаче с JSON’ами. В этом мне помогут инструменты Jolt и Avro. Пост пригодится новичкам и тем, кто выбирает инструмент для решения схожей задачи.
Что делает наша команда
Команда работает с данными по рекрутингу — с любой аналитикой, которая необходима персоналу подбора сотрудников. У нас есть различные внешние или внутренние источники, из которых с помощью NiFi или Apache Spark мы забираем данные и складируем к себе в хранилище (по умолчанию Hive, но есть еще PostgreSQL и ClickHouse). Этими же инструментами мы можем брать данные из хранилищ, создавать витрины и складывать обратно, предоставлять данные внутренним клиентам или делать дашборды и давать визуализацию.
Описание задачи
У нас есть внешний сервис, на котором рекрутеры работают с подбором. Сервис может отдавать данные через свою API, а мы эти данные можем загружать и складировать в хранилище. После загрузки у нас появляется возможность отдавать данные другим командам или работать с ними самим. Итак, пришла задача — нужно загрузить через API наши данные. Дали документацию для загрузки, поехали. Идем в NiFi, создаем пайплайн для запросов к API, их трансформации и складывания в Hive. Пайплайн начинает падать, приходится посидеть, почитать документацию. Чего-то не хватает, JSON-ы идут не те, возникают сложности, которые нужно разобрать и решить.
Ответы приходят в формате JSON. Документации достаточно для начала загрузки, но для полного понимания структуры и содержимого ответа — маловато.
Мы решили просто загружать все подряд — на месте разберемся, что нам нужно и как мы это будем грузить, потом пойдем к источникам с конкретными вопросами. Так как каждый метод API отдает свой класс данных в виде JSON, в котором содержится массив объектов этого класса, нужно построить много таких пайплайнов с обработкой разного типа JSON’ов. Еще одна сложность — объекты внутри одного и того же класса могут отличаться по набору полей и их содержимому. Это зависит от того, как, например, сотрудники подбора заполнят информацию о вакансии на этом сервисе. Этот API работает без версий, поэтому в случае добавления новых полей информацию о них мы получим только либо из данных, либо в процессе коммуникации.

Меня зовут Дмитрий Курганский, я Tech Lead команды MLOps в Банки.ру.
Мы работаем над тем, чтобы грамотно организовать и ускорить этапы жизненного цикла ML. В этой статье поделюсь нашим опытом применения Embedding: от запуска Яндекс Data Proc кластера через Airflow до оптимизации этапа применения Embedding с помощью Spark.
Материал в целом будет актуален для этапа применения (inference) любых моделей для больших наборов данных, работающих в batch режиме по расписанию.

В 2024 году ни одна крупная компания в мире, работающая с CAD (BIM) данными, не получает доступ к данным из CAD (BIM) программ через API или плагины.
Все крупные компании, работающие с форматами CAD (BIM), работают с определенными SDK, а форматы, содержащие данные о строительных проектах становятся взаимозаменяемы.











Это мой вольный перевод статьи "Why You Should Start Writing Spark Custom Native Functions", которая вдохновила меня на некоторые собстенные изыскания по данной теме. Их результат я планирую опубликовать позже, а пока выношу на ваш суд этот перевод.
Статья на примере реализации функции по генератации UUID рассматривает, как писать Spark native функции, которые были бы "прозрачны" для Catalyst (в отличии от UDF, которые являются "черными ящиками" для него). Сравнение производительности ожидаемо показывает, что Catalyst Expressions значительно превосходят UDF при увеличении размера данных.
Кому интересно узнать, как писать Spark native функции - прошу под кат.
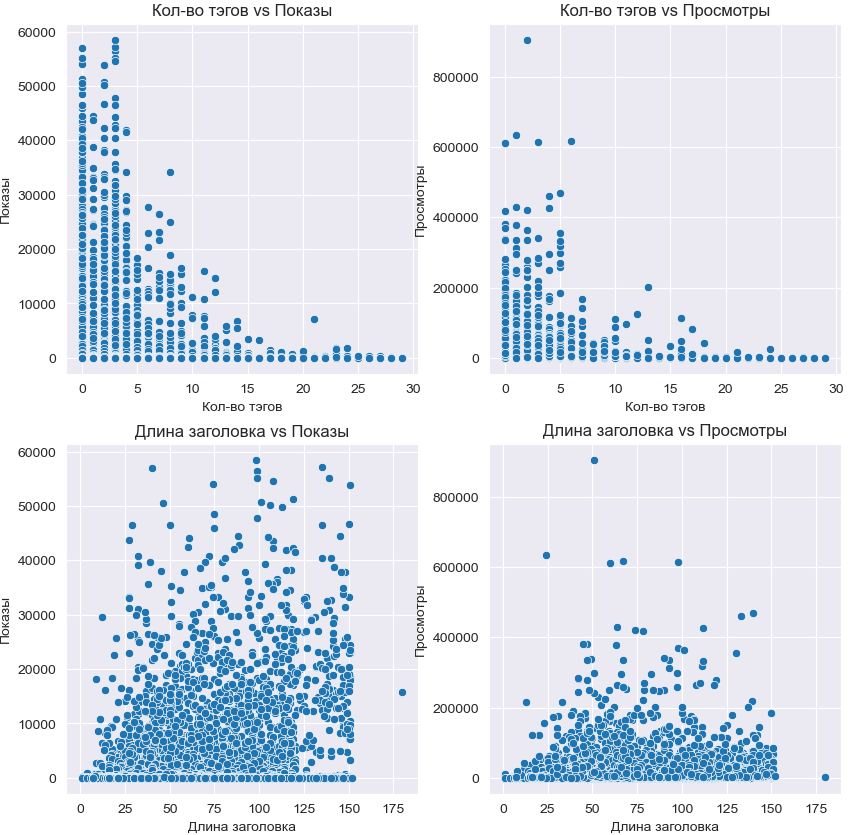
Привет, habr! 👋
Вы когда-нибудь задумывались, почему некоторые посты набирают тысячи просмотров, а другие остаются незамеченными? Ясно, что Content is King, но есть ли дополнительные факторы, которые влияют на успешность поста?
Мы решили не гадать, а действовать. 🔍
Соскрейпили все посты на VC, а затем посчитали корреляции, чтобы выяснить, что же на самом деле привлекает внимание аудитории.

Всем привет! Меня зовут Амир, я Data Engineer в компании «ДЮК Технологии». Расскажу, как мы спроектировали и реализовали на Apache Druid хранилище разрозненных табличных данных.
В статье опишу, почему для реализации проекта мы выбрали именно Apache Druid, с какими особенностями реализации столкнулись, как сравнивали методы реализации датасорсов.

Привет, Хабр! Доводилось ли вам тратить долгие бесплодные часы в попытке настроить коннекторы Kafka Connect, чтобы добиться адекватного потока данных? Мне, к сожалению, доводилось. Представляю вашему вниманию перевод статьи "How to Tune Kafka Connect Source Connectors to Optimize Throughput" автора Catalin Pop. Это прекрасное руководство от Confluent, где подробно и с примером описывается, как настроить Source коннекторы.

Недавно ко мне обратились знакомые, которые активно впиливали LLM в своей продукт, однако их смущала стоимость такого решения - они платили около 8$/час за Huggingface inference Endpoint 24/7, на что уходили просто невиданные ~100 тысяч долларов в год. Мне нужно было заресерчить какие есть способы развертывания больших текстовых моделей, понять какие где есть проблемы и выбрать оптимальных из них. Результатами этого ресерча и делюсь в этой статье)
Данная статья представляет подход к решению задачи сбора и агрегации метрик от Ingress Nginx Controller для извлечения геоданных с помощью GeoIP2 и их визуализации в Elasticsearch.

Привет, меня зовут Луиза, я инженер данных в ЮMoney — работаю здесь уже год. Мы собираем данные, структурируем их, храним и создаём аналитические решения, например OLAP-кубы и дашборды. Департамент разделён на несколько команд, у каждой своя предметная область. За год я превратилась в крепкого джуна и не собираюсь останавливаться.
В этой статье расскажу, как я попала на стажировку, чем занималась в первые месяцы и что изучала, чтобы перейти на новый уровень. Хочу, чтобы моя история мотивировала не бояться откликаться на вакансии уровня мидл+, даже если у вас нет опыта в дата-инженерии, но есть желание развиваться. Может оказаться, что в компании ждали именно вас.



