

Российские вендоры в апреле не отдыхали и активно выпускали новое железо. Среди отечественных новинок — серверы, диски и системы хранения данных. Уже присматриваете новое железо для своих серверов? Тогда добро пожаловать под кат!

VRackDB - это простая In Memory Graphite like база данных, предназначенная для хранения временных рядов (графиков). (TypeScript)
Мне, как автору базы, хотелось бы немного рассказать о ее особенностях и области применения. Покажу немного картинок, немного кода, возможно даже, немного полезной для вас информации. В общем все как обычно.

Вы, конечно, знаете, что сервер является сердцем любого онлайн-сервиса или офисной сети. Именно серверы обеспечивают работоспособность наших любимых веб-сайтов, приложений, игр и социальных сетей, а нам позволяют открывать их 24 часа в сутки 7 дней в неделю. Эта статья — для новичков, которые не задумывались, чем отличаются серверы друг от друга, какими они бывают, а также коснемся вопроса выбора сервера.
Дисклеймер: это вводный материал в серии, посвященной серверам. Тут мы разберем основные понятия. А для тех, кто с серверами "на ты", совсем скоро выйдут материалы, в которых мы более глубоко разберем различные аспекты, касающиеся серверов, с профессиональной точки зрения.

Сегодня, когда объёмы данных постоянно растут, а терять их становится всё критичнее, использование внешнего накопителя часто становится необходимостью. У каждого из нас есть файлы, которыми мы дорожим — от рабочих документов до фотографий с домашними питомцами. При этом у жёстких дисков есть срок службы и вероятность отказа в самый неподходящий момент. У меня был подобный опыт с накопителем Seagate и ошибкой «муха СС». С тех пор я в обязательном порядке дублирую все важные файлы в облако и ещё на один диск.
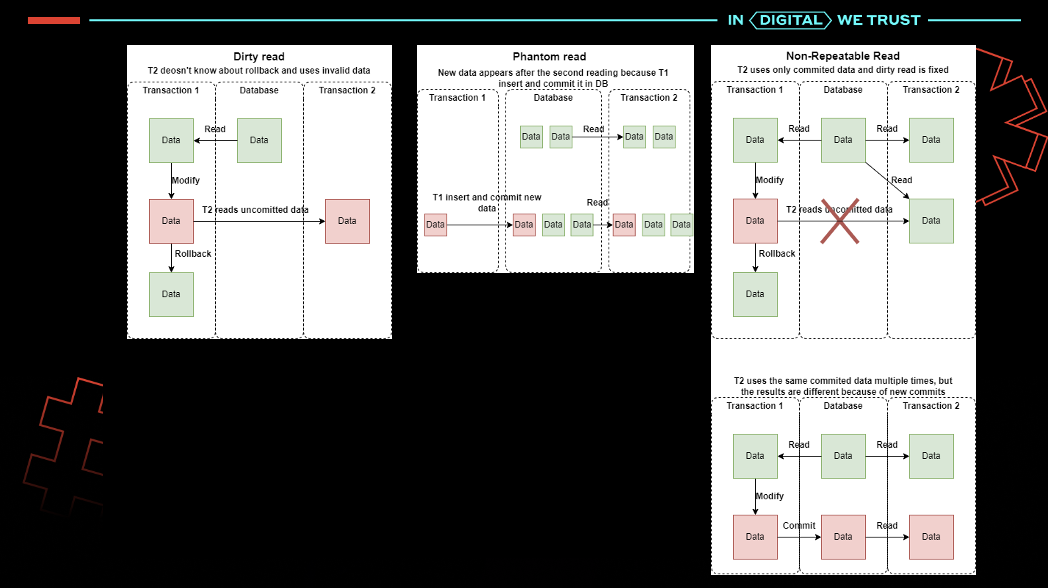
Данный материал позволит вам подготовиться к собеседованию, освежить знания или познакомиться с такими терминами как транзакции, ACID и уровни изоляции.
Важно отметить, что речь пойдет о реляционных базах данных, которые наилучшим образом подходят для транзакций и соответствуют критериям ACID.


Приветствую всех! Я Геннадий Гужов, студент Высшей школы экономики и продакт-менеджер в компании "Солдвиг", специализирующейся на контейнерных дата-центрах. В этой статье я расскажу о контейнерных дата-центрах: что они из себя представляют, из чего состоят и какие преимущества они предлагают. Мы изучим ключевые аспекты, помогающие понять, почему эта инфраструктура становится важной частью современного бизнеса. Будьте в курсе последних тенденций и развития технологий — ваше знание — ваша сила!
Давайте начнем с основ: что такое дата-центр?
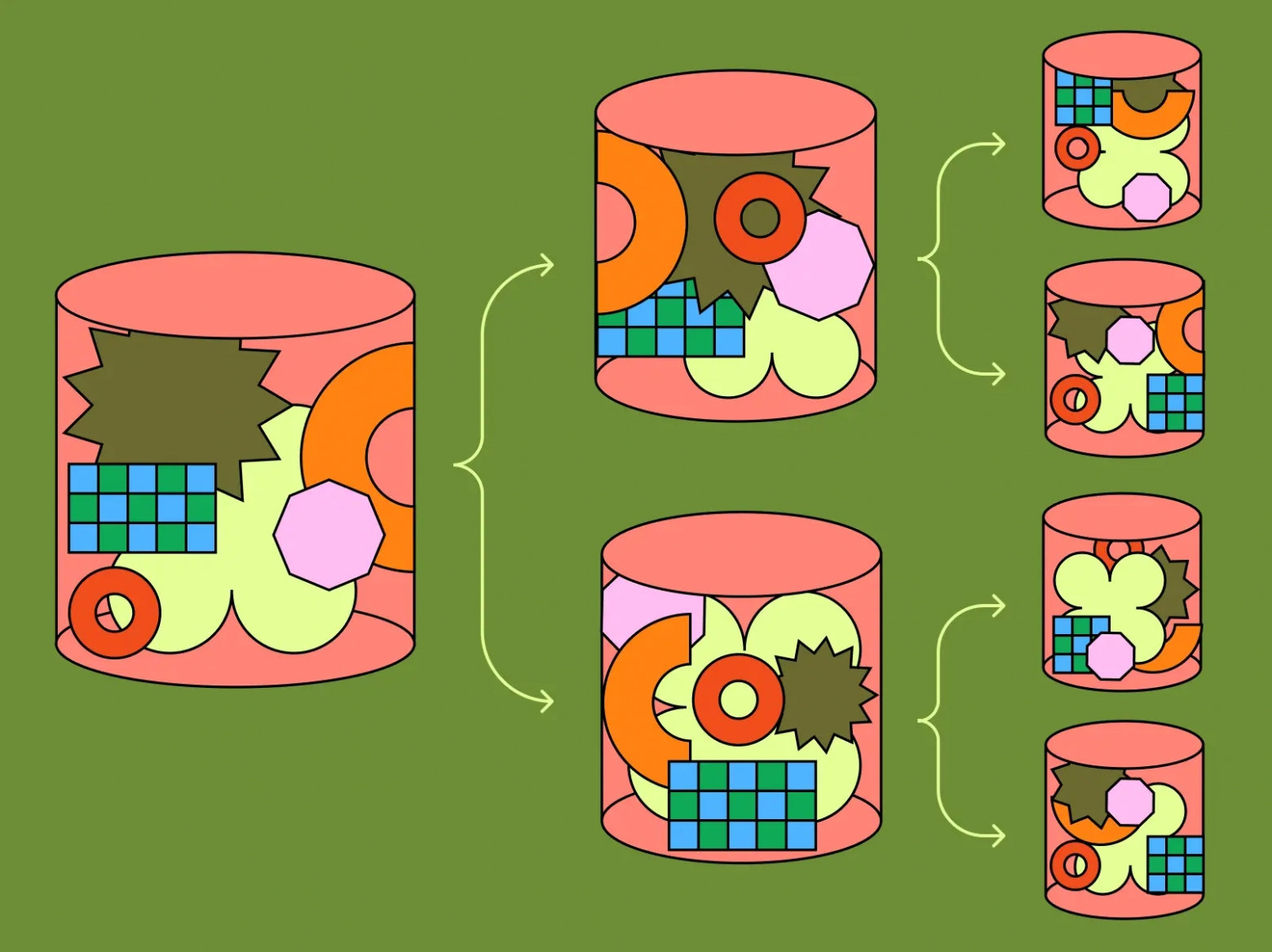
О нашем девятимесячном пути к горизонтальному шардингу Postgres-стека Figma и о возможности обеспечения (почти) бесконечной масштабируемости.
Вертикальное разбиение было относительно простым и важным инструментом масштабирования, позволившим нам быстро добиться существенных улучшений. Кроме того, оно стало важным этапом на пути к горизонтальному шардингу.
С 2020 года стек баз данных Figma вырос почти в сотню раз. Это хорошая проблема, ведь она означает, что наш бизнес расширяется. Но в то же время она стала причиной технических сложностей. В течение последних четырёх лет мы усиленно старались не отставать от прогресса и избегать потенциальных проблем, связанных с ростом. В 2020 году у нас работала единственная база данных Postgres, которая хостилась на самом большом физическом инстансе AWS, но к концу 2022 года мы уже создали распределённую архитектуру с кэшированием, репликами для чтения и десятком вертикально разделённых баз данных. Мы разбили группы связанных таблиц (например, «Figma files» или «Organizations») на отдельные вертикальные разделы, что позволило нам обеспечить удобство инкрементального масштабирования и оставить достаточно пространства для дальнейшего роста.

Делаем резервное копирование кластера ClickHouse: простая инструкция
Меня зовут Леонид Блынский и я администратор баз данных в Лиге Цифровой Экономики. В этой небольшой статье расскажу, как я делаю резервное копирование кластера ClickHouse размером 20 ТБ.
Документация по резервному копированию довольно небольшая и содержит инструкции по созданию резервных копий отдельной инсталляции СУБД. К сожалению, информации о том, как создавать резервные копии кластера, практически нет. Как и нет промышленного решения для управления бэкапом.

В статье описывается практическое применение популярных Open-Source технологий в области интеграции, хранения и обработки больших данных: Apache NiFi, Apache Airflow и Greenplum для проекта по аналитике учета вывоза отходов строительства.
Статья полезна специалистам и руководителям, которые работают с данными решениями и делают ставку на них в части импортозамещения аналогичных технологий. Статья дает обзор основных сложностей внедрения на примере реального кейса, описывает архитектуру и особенности при совместном использовании решений.

Yandex Query Language (YQL) — универсальный декларативный язык запросов к системам хранения и обработки данных, разработанный в Яндексе. А ещё это один из самых нагруженных сервисов: YQL ежедневно обрабатывает около 800 петабайт данных и 600 000 SQL-запросов, и эти показатели постоянно растут.
Изначально YQL основывался на операциях MapReduce, которые эффективны для больших данных. Но для средних объёмов данных (до 50 Гб, которые составляют около 60% запросов) этот подход оказался неоптимальным, потому что нужно было обмениваться данными между операциями через диск. Поэтому разработчики создали новый более гибкий стриминговый движок, который значительно ускоряет обработку данных за счёт выполнения всех вычислений в памяти.
В этой статье я хочу рассказать о подходах и технологиях в разработке систем для обработки данных на примере YQL. Основное внимание я уделил переходу от MapReduce к стриминговому движку, который обеспечивает более эффективную обработку данных, вмещающихся в память, и который доступен в опенсорсе.

Всем привет! Меня зовут Амир, я Data Engineer в компании «ДЮК Технологии». Расскажу, как мы спроектировали и реализовали на Apache Druid хранилище разрозненных табличных данных.
В статье опишу, почему для реализации проекта мы выбрали именно Apache Druid, с какими особенностями реализации столкнулись, как сравнивали методы реализации датасорсов.
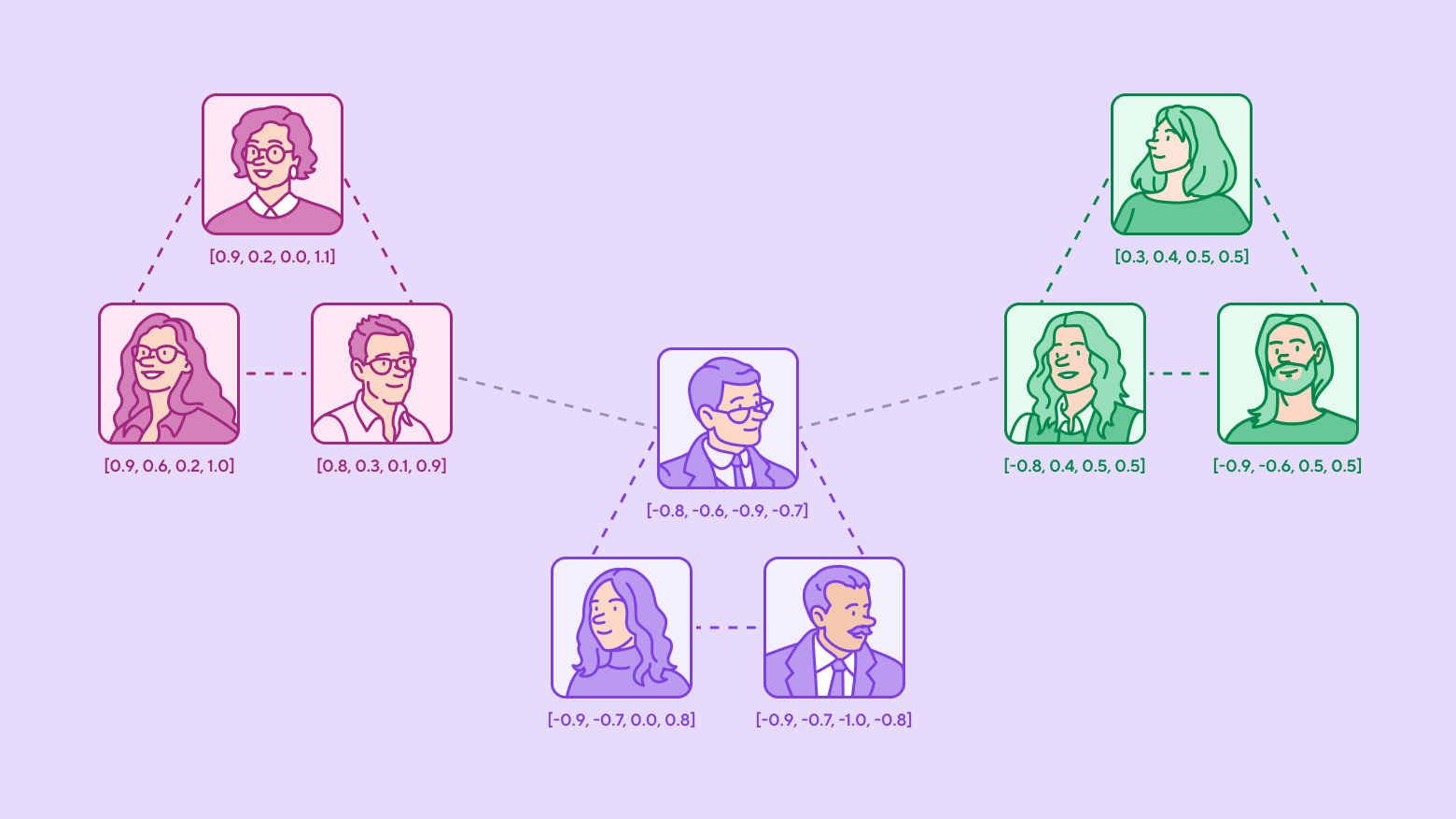
Только изучили один инструмент, как сразу же появились новые? Придется разбираться! В статье мы рассмотрим новый тип баз данных, который отлично подходит для ML задач. Пройдем путь от простого вектора до целой рекомендательной системы, пробежимся по основным фишкам и внутреннему устройству. Поймем, а где вообще использовать этот инструмент и посмотрим на векторные базы данных в деле.











В статье рассказываем о том, кому стоит задуматься о внедрении DWH, как сократить вероятность ошибок на этапе разработки проекта, выбрать стек, методологию и сэкономить ИТ-бюджеты.

Иван Якунин, продуктовый аналитик команды Fintech Marketplace, рассказал про то, как в Авито работают с Vertica, и на примерах объяснил, что такое проекции, и когда их стоит использовать.

В сегодняшней статье мы начнем знакомиться с универсальной и высокопроизводительной кластерной вычислительной платформой Apache Spark, научимся разворачивать данное решение и выполнять простейшие программы. При обработке больших объемов данных скорость играет важную роль, так как именно скорость позволяет работать в интерактивном режиме, не тратя минуты или часы на ожидание. Spark в этом плане имеет серьезное преимущество, обеспечивая высокую скорость, благодаря способности выполнять вычисления в памяти.

SSD killer — destroyer for your ssd
Привет, меня зовут Ваня, и вот коротенькая история о том, как я придумал и собрал одну штуку, и почему вам нужно срочно отдать мне все свои деньги.
А если серьезно, это устройство для оперативного аппаратного уничтожения данных вместе с носителем. По своей сути это аналог чеховского ружья, у которого цель выстрелить в нужный момент.
Viam supervadet vadens (дорогу осилит идущий)
Есть много счастливчиков, которым повезло работать в ситуации, когда объёмы по-настоящему огромны и требования кажутся невыполнимыми. Но есть те, кому по настоящем крупно повезло! Я говорю о тех, кто решал задачи в пространствах, где размерность больше 1.
Давайте разбросаем осколки по всей земле?
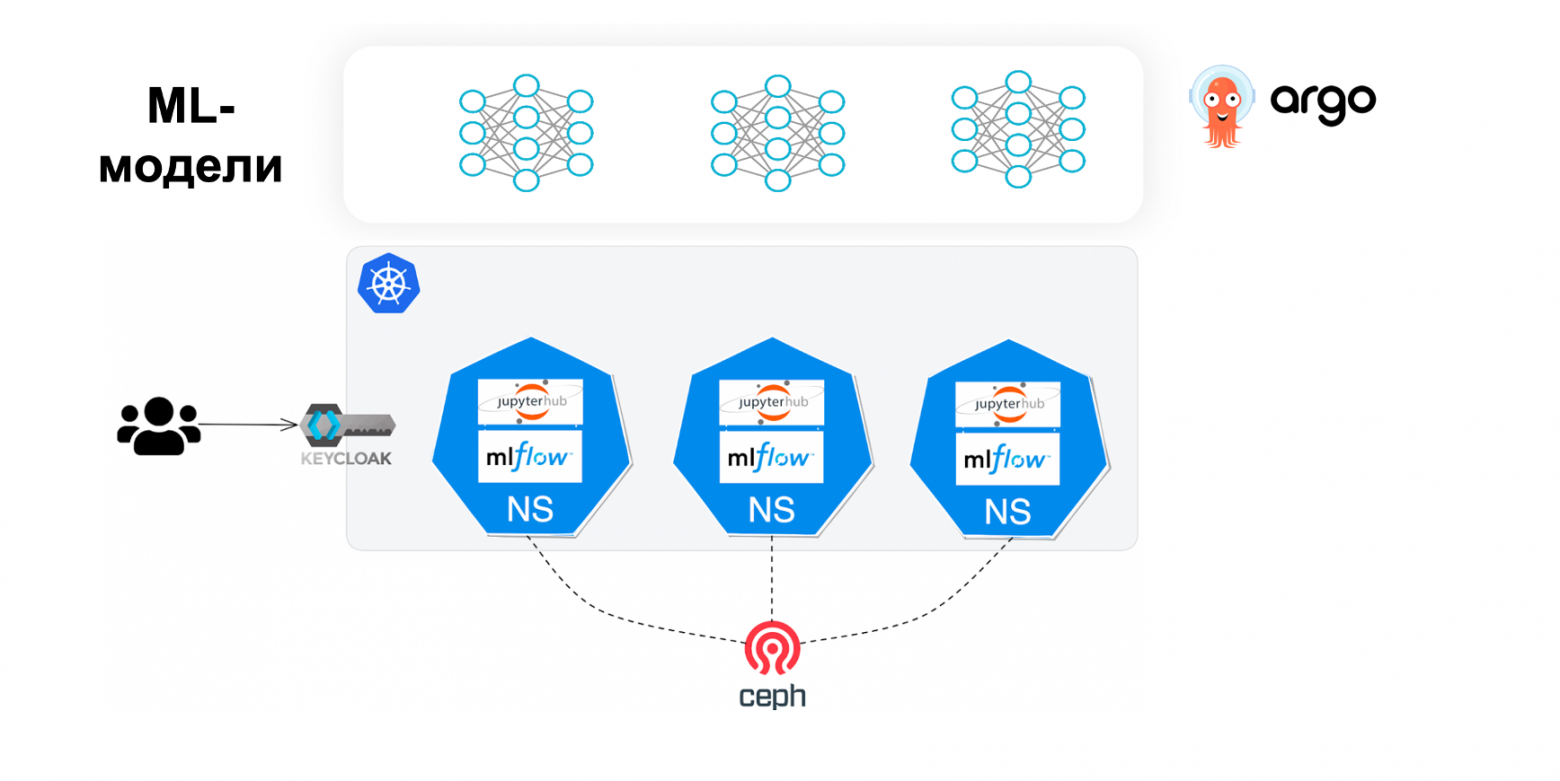
Привет, Хабр!
Мы в билайне любим машинное обучение. В какой-то момент моделей машинного обучения стало так много, что это вынудило нас решать определенные задачи. Я Дмитрий Ермилов, руковожу ML в дирекции по искусственному интеллекту и цифровым продуктам. О решении одной такой задачи и будет этот рассказ.
Давайте представим, что у вас в компании большое количество моделей машинного обучения, каждая из которой может зависеть от нескольких десятков до нескольких тысяч признаков (фич). Причем разные модели могут зависеть от одних и тех же фич. Неожиданно случается несчастье, и одна из популярных фич ломается. Может произойти поломка на уровне подготовки данных, могут измениться внешние источники, отвалиться интеграции и прочее. Что делать с этим знанием? Конечно, бежать в продуктовые команды и кричать, что модели, которые зависят от этой фичи, могут деградировать, то есть их метрики качества могут снизиться. Вопрос только в том, какие модели могут деградировать и в какие команды бежать?
Напомним, в каких условиях мы анализируем данные и строим модели машинного обучения.

Всем привет!
В этой статье возьмем за основу пару таблиц и пройдемся по планам запросов по нарастающей: от обычного селекта до джойнов, оконок и репартиционирования. Посмотрим, чем отличаются виды планов друг от друга, что в них изменяется от запроса к запросу и разберем каждую строчку на примере партиционированной и непартиционированной таблицы.



