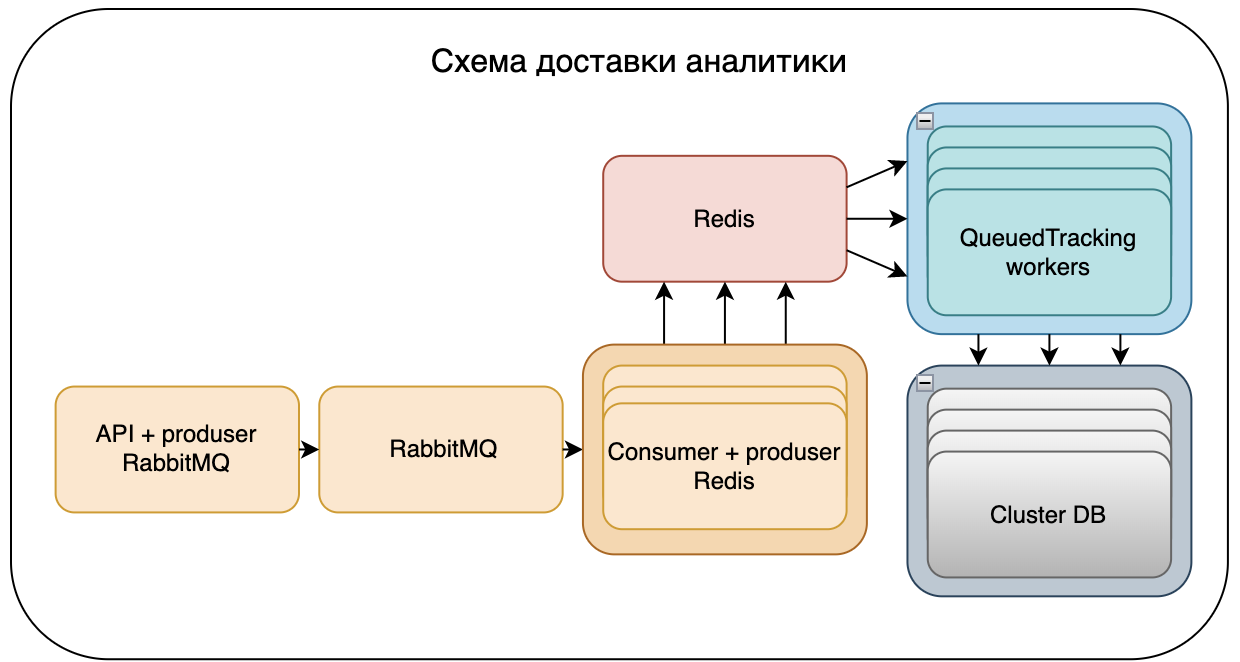
Долгожданный стандарт RFC9562 "Universally Unique IDentifiers (UUID)" с тремя новыми версиями идентификаторов UUID (6, 7 и 8) вместо малопригодного RFC4122 наконец-то вступил в силу. Я участвовал в разработке нового стандарта. Обзор стандарта можно посмотреть в статье.
Введенные новым стандартом идентификаторы седьмой версии UUIDv7 — это лучшее, что теперь есть для ключей баз данных и распределенных систем. Они обеспечивают такую же производительность, как и bigint. UUIDv7 уже реализованы в том или ином виде в основных языках программирования и в некоторых СУБД.
Сгенерированные UUIDv7 имеют все преимущества UUID и при этом упорядочены по дате и времени создания. Это ускоряет поиск индексов и записей в БД по ключу в формате UUID, значительно упрощает и ускоряет базы данных и распределенные системы. Неупорядоченность значений UUID прежде сдерживала использование UUID в качестве ключей и вынуждала разработчиков выдумывать собственные форматы идентификаторов или довольствоваться последовательными целыми числами в качестве ключей.
Черновик стандарта активно обсуждался на Хабре в апреле 2022 года в комментариях к статье "Встречайте UUID нового поколения для ключей высоконагруженных систем".
Разные участники разработки нового стандарта придерживались различных взглядов, и практически все обсуждавшиеся альтернативные варианты структуры UUIDv7 вошли в стандарт. Поэтому теперь перед разработчиками возникает вопрос, какую из множества возможных спецификаций UUIDv7 реализовывать и применять. Также для массового перехода на UUIDv7 нужна дополнительная функциональность, повышающая привлекательность UUIDv7 для разработчиков и бизнеса.
Предложенная мной ниже спецификация UUIDv7 с дополнительной функциональностью описывает максимально надежный и удобный вариант структуры UUIDv7 для самых сложных и высоконагруженных информационных систем. Функциональность упорядочена по приоритету реализации