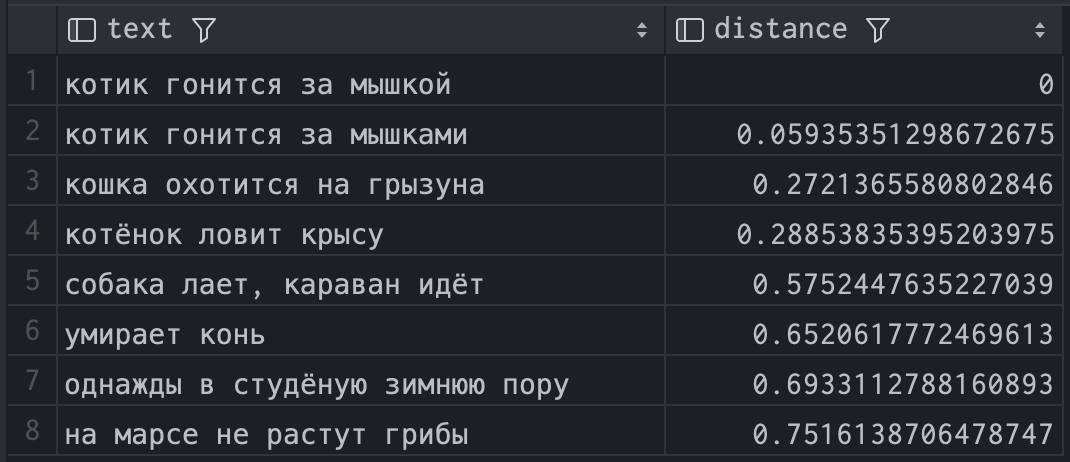
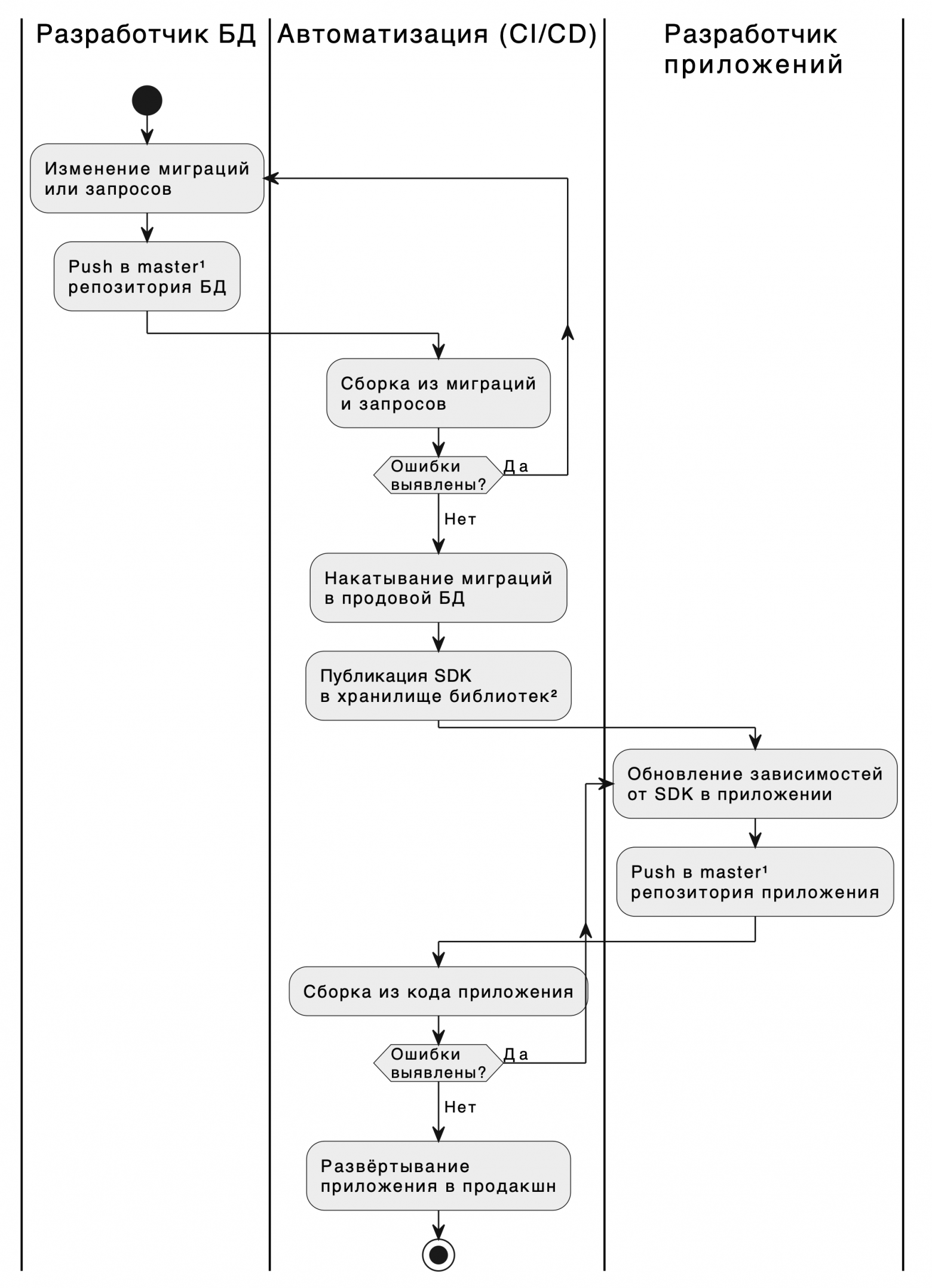
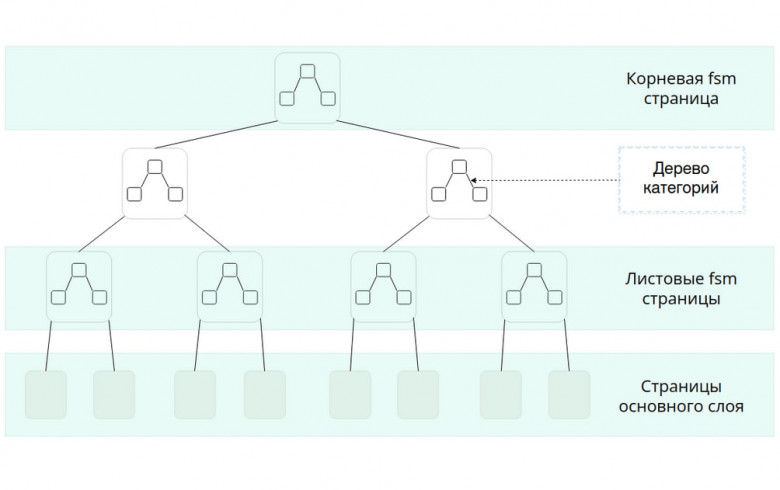
Как реализовать хранение и работу каталога папок в PostgreSQL? Есть большое количество вариантов. Но хочется, чтобы реализация выглядела лаконично, не нарушала прозрачность выполняемых операций, не вызывала блокировок, не требовала большого вовлечения клиента в специфику работы и т.д. Потому сегодня попробуем реализовать хранение древовидных структур и работу с ними без использования триггеров, блокировок, дополнительных таблиц (представлений) и внешних инструментов в SQL.