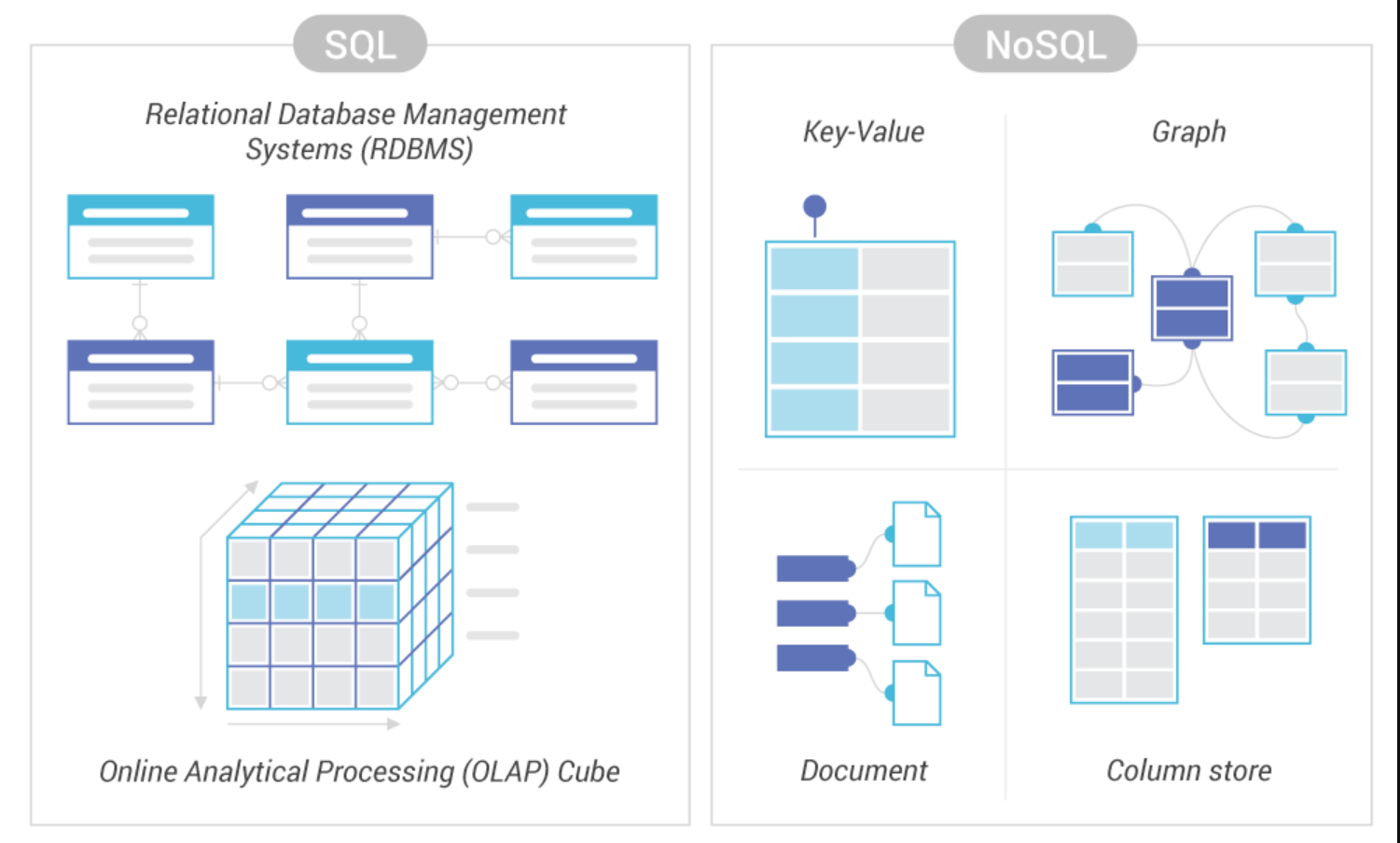
How do you deal with index fragmentation if your SQL server is working in high load environment with 24/7 workload without any maintenance window? What are the best practices for index rebuild and index reorganize? What is better? What is possible if you have only Standard Edition on some servers? But first, let's debunk few myths.
Myth 1. We use SSD (or super duper storage), so we should not care about the fragmentation. False. Index rebuild compactifies a table, with compression it makes it sometimes several times smaller, improving the cache hits ratio and overall performance (this happens even without compression).
Myth 2. Index rebuild shorten SSD lifespan. False. One extra write cycle is nothing for the modern SSDs. If your tempdb is on SSD/NVMe, it is under much harder stress than data disks.
Myth 3. On Enterprise Edition there is a good option: ONLINE=ON, so I just create a script with all tables and go ahead. False. There are tons of potential problems created by INDEX REBUILD even with ONLINE and RESUMABLE ON - so never run index rebuilds without controlling the process.
Finally, we will tackle the REBUILD vs REORGANIZE subject and what is possible to achieve if you have only Standard Edition.