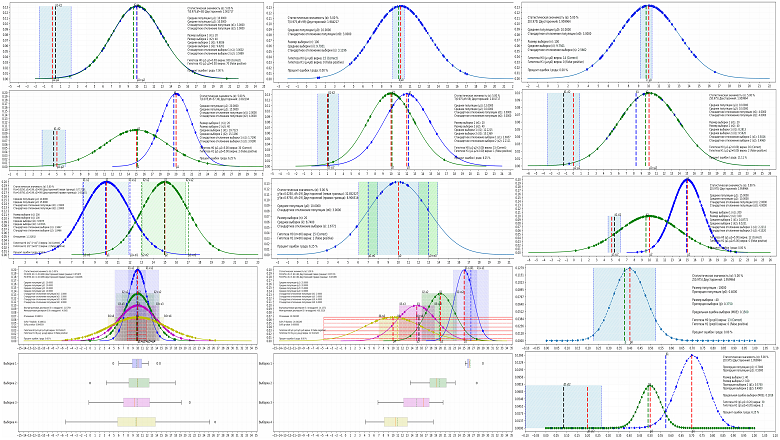
В предыдущей статье Метрика в машинном обучении сложных систем, алгоритм и программный код предложена формула для отношения сигнала к шуму в сложных нелинейных системах с тенденцией к самоорганизации. С опытом применения в обработке данных электрокардиограмм, землетрясения. Сложной системой является и биологическая нейросеть.
Искусственные нейронные сети возникли в качестве попытки моделировать организацию и функционирование биологических нейронных сетей – сетей нервных клеток живого организма. В существующих алгоритмах искусственного интеллекта ключевым звеном является решение задачи оптимизации и при этом остаётся вопрос - решает ли биологическая нейронная сеть задачу оптимизации? Задача оптимизация - это нахождение экстремумов целевой функции в процессе проектирования параметров системы. Под задачу оптимизации сформировался функциональный подход, который предполагает рассмотрение объекта как комплекса выполняемых им функций, а не как набора элементов и их взаимосвязей.
Ключевым условием в постановке задачи оптимизации является наличие управляющих факторов или заданных внешних правил. Например, выбор оптимального хода по правилам игры в шахматы или в чайнике вода превращается в пар и управляющим фактором выступает температура, где применимы постановки задач оптимизации. При детонации взрывчатых веществ жидкость превращается в газы при отсутствии управляющих факторов. Отсутствуют внешние управляющие факторы в лавинообразных процессах.
Отсутствие управляющих факторов и масштабная инвариантность процессов самоорганизованной критичности (SOC) не являются интуитивно понятными и привычными. Будет очевидной реакция некоторых читателей – «ничего не понимаю», хотя речь идёт об активности нашего собственного мозга.