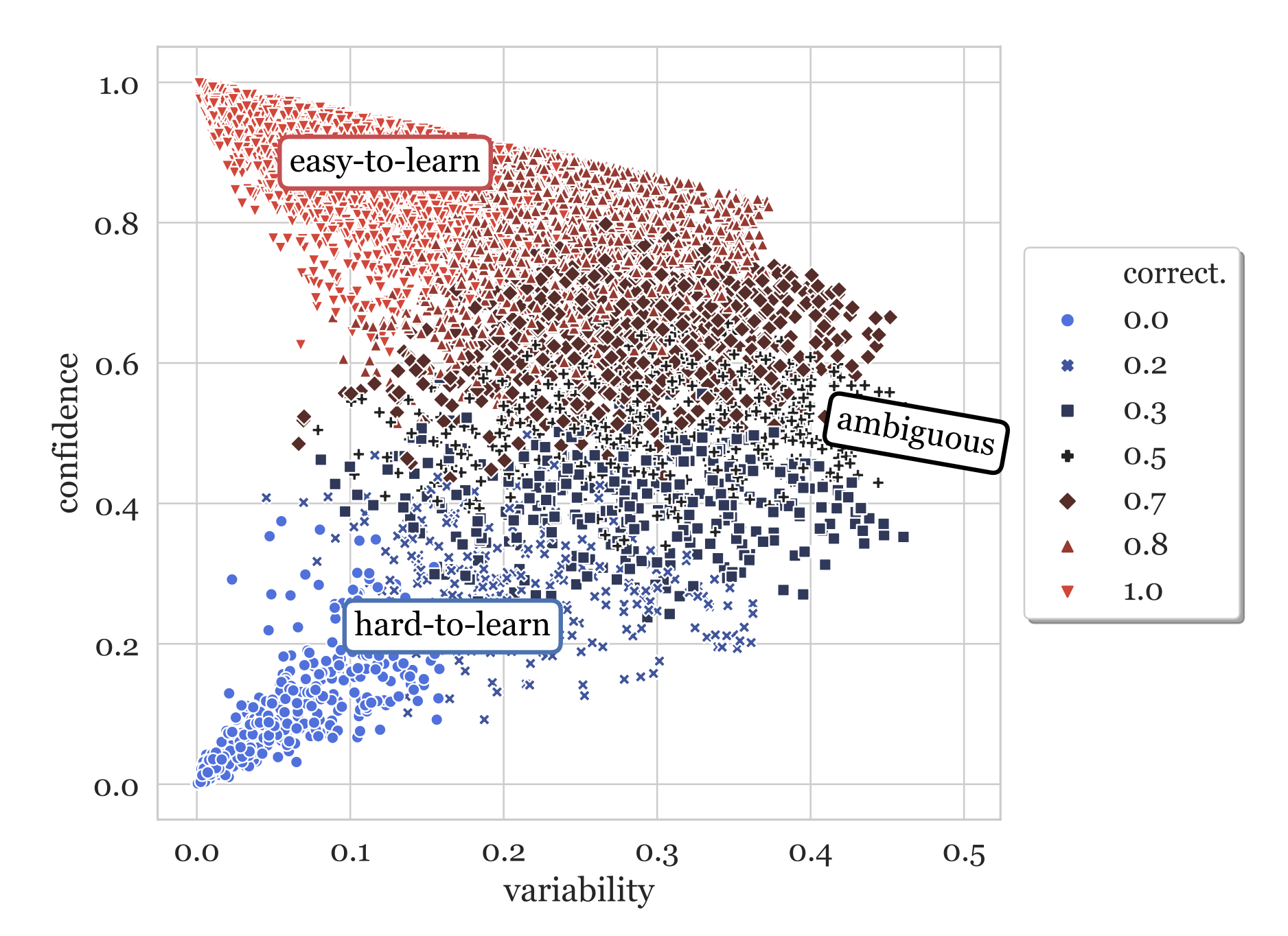
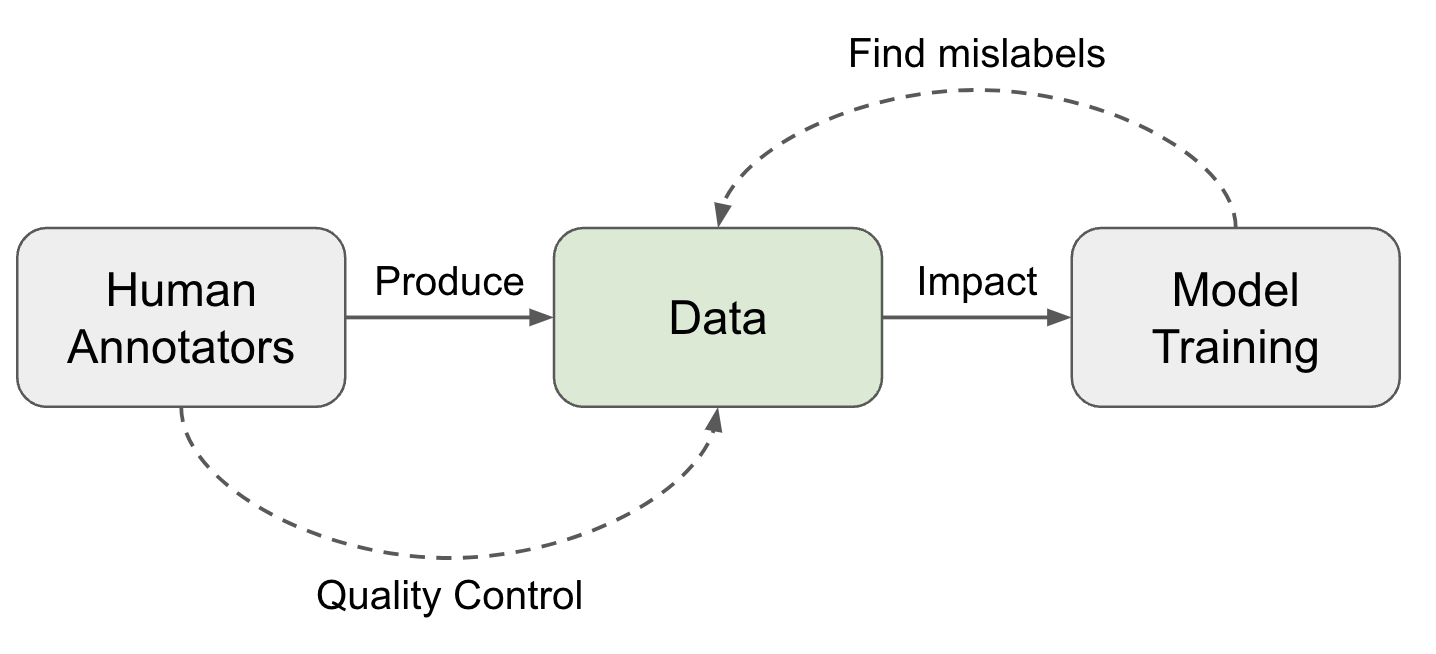
Очевидный для ML-инженера факт: если на вход модели подать мусор — на выходе тоже будет мусор. Это правило действует всегда, независимо от того, насколько у нас крутая модель. Поэтому важно понимать, как ваши данные будут храниться, использоваться, версионироваться и воспроизведутся ли при этом результаты экспериментов. Для всех перечисленных задач есть множество различных инструментов: DVC, MLflow, W&B, ClearML и другие. Git использовать недостаточно, потому что он не был спроектирован под требования ML. Но есть инструмент, который подходит для версионирования данных и не только — это ClearML. О нем я сегодня и расскажу.