

CDC вам не "Centers for Disease Control and Prevention" а "Change data capture". В статье рассказано какие есть виды CDC и как реализовать один из CDC при помощи Debezium.
CDC вам не "Centers for Disease Control and Prevention" а "Change data capture". В статье рассказано какие есть виды CDC и как реализовать один из CDC при помощи Debezium.

Вдохновившись прошлогодним опытом, мы продолжили начинание и снова проводим конкурс по SQL на международной олимпиаде «IT-Планета».
Конкурс состоит из трех этапов. Заочный теоретический тест собрал почти 3000 человек, из которых на следующий этап мы отобрали примерно 200. Вопросы для этого этапа были подготовлены моим коллегой, Евгением Давыдовым.
Второй этап — также заочный. Здесь участником было предложено подумать над пятью задачами моего авторства, о которых я сегодня и хочу рассказать.
Третий — очный — этап пройдет в конце мая; постараюсь не затягивать с отчетом, но пока храню интригующее молчание.
Поскольку все вводные слова про мотивацию я уже сказал в прошлый раз, сразу приступим к делу.

PostgreSQL очень популярная СУБД.
Её используют во многих проектах, как новички, так и профессионалы. Однако не все понимают, как именно работает данная система и какое у неё внутренне устройство.
Давайте разберемся вместе на основе книги "PostgreSQL 16 изнутри" и официальной документации!

Как реализовать хранение и работу каталога папок в PostgreSQL? Есть большое количество вариантов. Но хочется, чтобы реализация выглядела лаконично, не нарушала прозрачность выполняемых операций, не вызывала блокировок, не требовала большого вовлечения клиента в специфику работы и т.д. Потому сегодня попробуем реализовать хранение древовидных структур и работу с ними без использования триггеров, блокировок, дополнительных таблиц (представлений) и внешних инструментов в SQL.

Когда я пришёл работать в компанию GreenData шесть лет назад, мои задачи были достаточно стандартными для аналитика, который работает с low-code решениями. Работа с объектной моделью, написание алгоритмов, настройка визуалов - всё что обычно выполняет начинающий специалист в данной области. Однако в процессе моей работы и роста иногда я сталкивался с необходимостью разбираться в тонкостях работы Java, а именно с ошибками, которые возникали в процессе её исполнения.
Эти встречи с Java сначала были случайностью, но со временем превратились в моё новое профессиональное увлечение. Каждый случай сбоя или нестандартного поведения программы становился для меня вызовом; я понял, что за ошибками стоят не просто коды и сообщения, а целые истории о том, как работает система. Этот интерес постепенно перерос в глубокое погружение в мир Java-логов, благодаря чему я стал одним из ведущих экспертов по анализу программных сбоев в компании.

Всем привет!
Как вы знаете, многие поставщики ПО ушли с российского рынка ввиду введённых санкций и многие компании столкнулись с необходимость заняться импортозамещением в кратчайшие сроки. Не стал исключением и наш заказчик. Целевой системой, на которое было принято решение мигрировать старое хранилище, стал Greenplum (далее GP) от компании Arenadata.
Этой статьей мы запускаем цикл материалов посвященных Greenplum. В рамках цикла мы разберем, как вообще устроен GP и как выглядит его архитектура. Постараемся выделить must have практики при работе с данным продуктом, а также обсудим, как можно спроектировать хранилище на GP, осуществлять мониторинг эффективности работы и многое другое. Данный цикл статей будет полезен как разработчикам БД, так и аналитикам.

Сначала запрос адаптирован для работы в PostgreSQL 15.6.
Затем работа запроса проверена на достаточно объемной иерархии - в качестве источника данных использована структура архива jdk-master.zip из OpenJDK 22

Привет, Хабр!
Как мы знаем, защита конфиденциальной информации — это неотъемлемая часть любого проекта. В статье поговорим про шифрование данных в PostgreSQL, а именно про шифрование с использованием как асимметричных, так и симметричных ключей.

Юбилейная - 10-я - конференция PGConf.Russia опередила юбилей компании (Postgres Professional исполнилось 9 лет). А самая первая - PGConf.Russia 2015 - даже опередила саму компанию: конференция прошла в феврале, а официальный день рождения Postgres Professional 1 апреля 2015.

В этой статье я максимально коротко и просто объясню принцип распознавания, хранения и поиска лиц в базе данных. В качестве примера будет использована библиотека Insightface и база данных PostgreSQL.
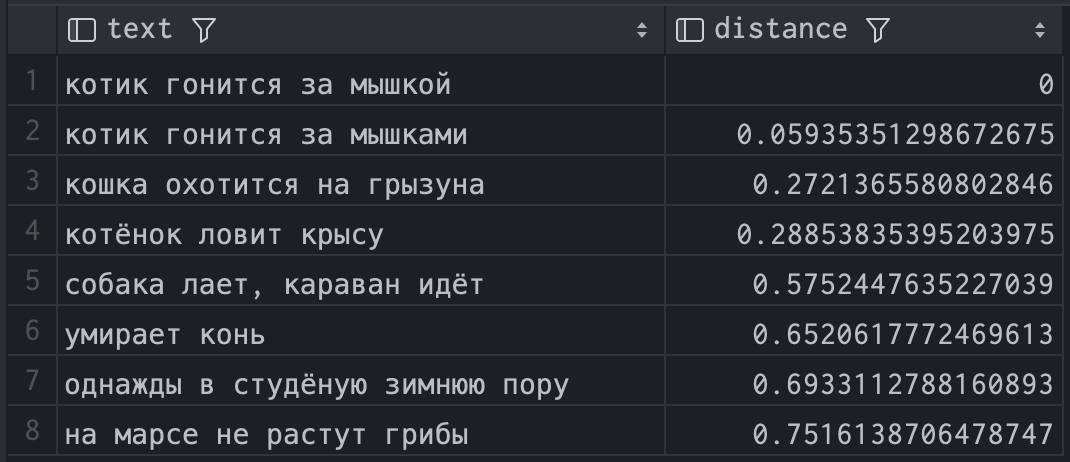
Казалось бы, в посгресе и так есть неплохой полнотекстовый поиск (tsvector/tsquery), и вы из коробки можете проиндексировать ваши тексты, а потом поискать по ним. Но на самом деле это не совсем то, что нужно — такой поиск работает лишь по чётким совпадениям слов. Т.е. postgres не догадается, что "кошка гонится за мышью" — это довольно близко к "котёнок охотится на грызуна". Как же победить такую проблему?
TLDR:

У одного из клиентов нашей системы мониторинга PostgreSQL серверов возникла проблема сильного замедления запросов при запуске базы в Docker. В этой статье расскажем о возможных последствиях использования PostgreSQL в Docker с конфигурацией по умолчанию.

Эта статья носит своей целью продемонстрировать другой подход в анализе проблем производительности в системах 1С:Предприятие с применением журнала регистрации (ЖР) и технологического журнала (ТЖ).
Напомню, что ЖР логирует действия пользователей — кто, когда в каком объекте внес изменения, с какого компьютера, каким сеансом и т. п. ТЖ — это средство для логирования уже самой платформы. Для расследования проблем производительности информация из журналов очень полезна, но основное время уходит на её поиск, сопоставление с другими метриками и счетчиками мониторинга.
При проведении расследований мы сами часто сталкиваемся с проблемой длительной обработки и сопоставления данных журналов 1С с остальными метриками. И вот наконец руки дошли до парсинга журналов. С точки зрения анализа производительности все данные журналов нам не нужны. А какие нужны?
Вот! В этом как раз вся «соль» идеи.












HyperLogLog принадлежит к категории вероятностных структур данных, которые позволяют аппроксимировать количество уникальных элементов в больших наборах данных с удивительно низким потреблением памяти. HLL использует логарифмическую память.
В PostgreSQL HyperLogLog предоставляется как расширение, которое можно использовать для оценки уникальности пользователей, событий или любых других элементов.
В этой статье рассмотрим, как реализован HLL в PostgreSQL.
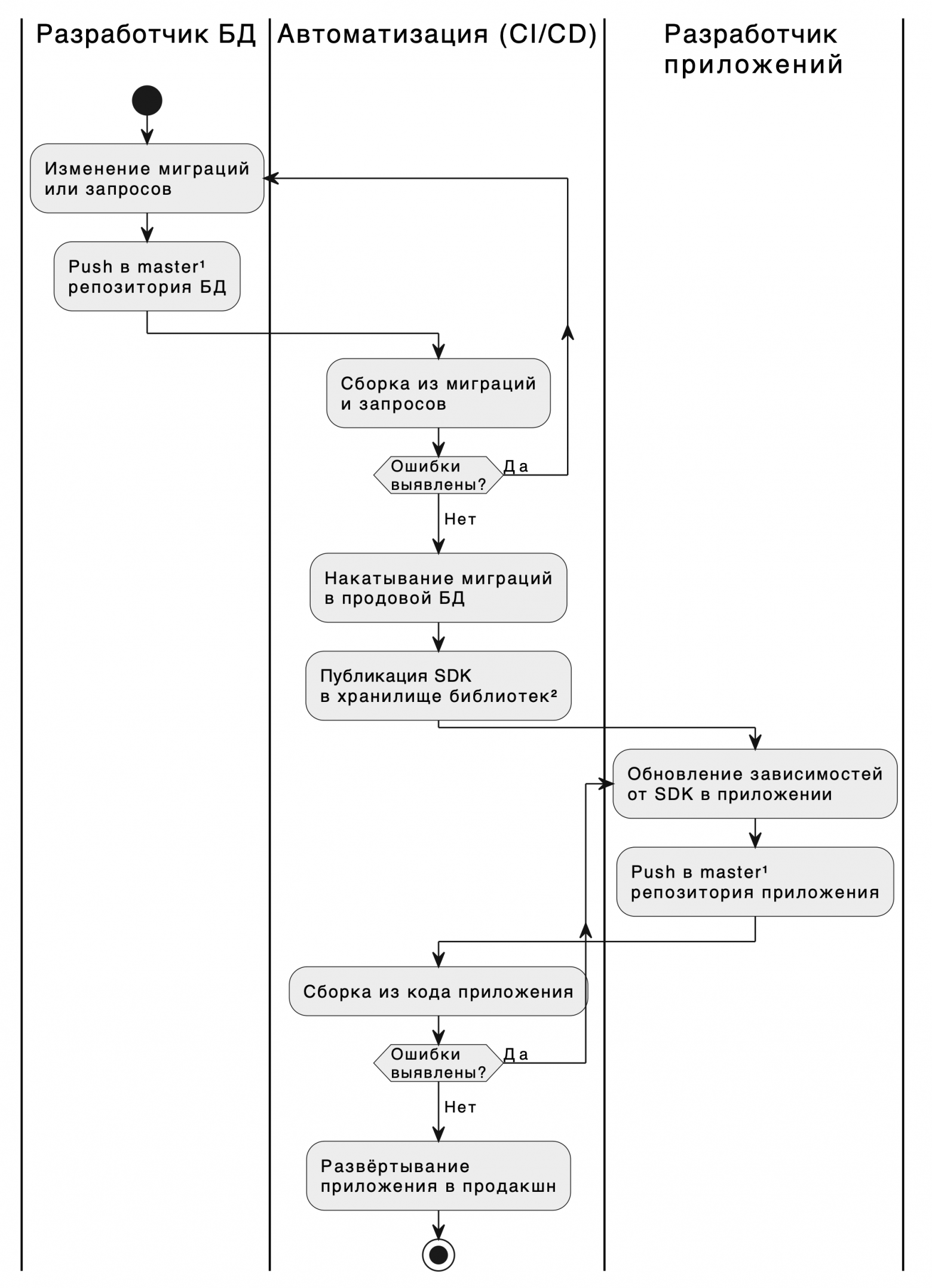
В статье рассматривается Continuous Deployment для БД с бесшовными релизами за счёт обратно-совместимых обновлений и автоматизации проверок совместимости с помощью подхода DB-First.

В данной публикации я поделюсь двумя основными причинами, по которым я предпочитаю избегать использования автоинкрементных полей в PostgreSQL и MySQL в будущих проектах. Вместо этого я предпочитаю использовать UUID-поля, за исключением случаев, когда есть очень веские аргументы против этого подхода.

В данной статье обсудим создание REST-сервиса в “реактивном” исполнении. Приведу примеры кода на Kotlin в двух вариантах: Reactor и coroutines

Когда я начинал писать своих первых ботов с использованием базы данных, их код был очень плохим: он расходовал лишние ресурсы, а также была плохая архитектура проекта. Поэтому я хочу поделиться с вами своими знаниями, чтобы вы не наступали на те грабли, на которые наступал я. В проекте бота, который будет использован в качестве примера в данной статье, я использовал такие технологии, как aiogram, SQLAlchemy, alembic и Docker. В качестве СУБД выступает PostgreSQL. Приятного чтения!



