

CDC вам не "Centers for Disease Control and Prevention" а "Change data capture". В статье рассказано какие есть виды CDC и как реализовать один из CDC при помощи Debezium.
CDC вам не "Centers for Disease Control and Prevention" а "Change data capture". В статье рассказано какие есть виды CDC и как реализовать один из CDC при помощи Debezium.


В данной статье представлен обзор различных популярных (и не только) оптимизаторов, которые применяются в машинном и глубоком обучении, в частности для обучения нейронных сетей. Мы рассмотрим их основную идею и ключевые особенности, переходя от простых к более сложным концепциям. Помимо этого, в самом конце вы сможете найти большое количество дополнительных источников для более детального ознакомления с материалом.
CADE () - метод для приближения плотности вероятности, который можно эффективно использовать для поиска аномалий в данных. В этой статье я расскажу про этот метод, а также предоставлю пример реализации CADE на Python.

Сравниваем между собой качество 6 различных токенайзеров, включая новейший OpenAi Large|Small и E5 от Microsoft на задаче векторного поиска:
Ищем ответ на вопрос: В чем сила? в сборнике афоризмов и цитат.
Рассматриваются модели
text-embedding-ada-002
text-embedding-3-large
text-embedding-3-small
intfloat/multilingual-e5-large
ai-forever/ruBert-large
ai-forever/sbert_large_mt_nlu_ru
P.S. Бонусом сравнение как влияет токенайзер на качество задачи по классификации текста (30 классов).

По счастливой случайности я оказался резидентом Евросоюза, а значит, на меня также распространяется GDPR. Он позволяет мне запросить копию информации, которая хранится обо мне у всяких разных компаний. Я решил сделать это у Apple, и был неприятно удивлен.
Apple старается собирать как можно меньше данных.
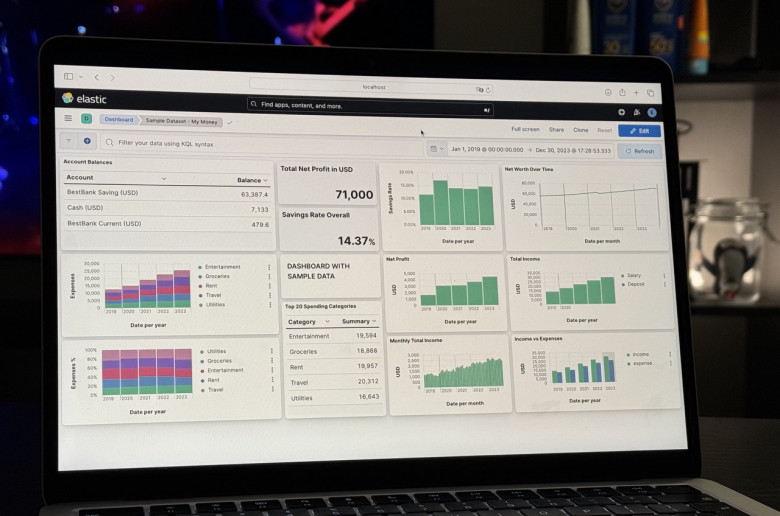
Привет, Хабр! Вот уже 7 с половиной лет я веду учет своих личных финансов в одном из многочисленных приложений. Всё это время оно неплохо закрывало базовые потребности в моменте, но с годами захотелось глубже проанализировать свою накопленную микро-бигдату и просмотреть на картину в целом. Желательно, в буквальном смысле: воспринимать информацию в виде визуализаций, диаграмм и дашбордов мне проще.
Поэксперементировав, я за несколько вечеров собрал себе решение на довольно нестандартной для таких целей платформе – Kibana. Как по мне, получилось неплохо. По горячим следам я описал этот кейс в своем англоязычном Твиттере и поделился им же в одном русскоязычном сообществе. Угадайте, откуда какой первый комментарий:
– А [зачем], собственно?
– Интересное решение! Я евангелист из Эластик – не хочешь на митапе выступить?
Выступить и правда было бы интересно. И в процессе подготовки презентации родилась эта статья. В ней я поделюсь своим опытом и подходом к личным финансам, расскажу о техническом стеке и воспроизведу по шагам процесс его трансформации. А также расскажу о том, как накопить и погасить технический долг, найти баланс, перестать беспокоиться и начать жить (но это не точно).

Сказ о том, как с помощью Opuna’ы сделать вашу RAG-систему чуточку (а может и не чуточку) эффективнее :)

В данной статье рассматривается влияние бакетизации на мощность статистических критериев в условиях различных распределений данных и при разном объеме выборки. Особое внимание уделено зависимости мощности критерия от количества бакетов и размера выборки. Исследование предоставляет важные выводы для проектирования и анализа A/B тестирования и других форм экспериментальных исследований.

Многие компании в последнее время ввели должность «ИИ-тренера» (AI-тренера), при этом просто разметчики/ассесоры никуда не делись. Что это — просто красивая обертка нейминга над тем же самыми или что-то концептуально новое?
Давайте попробуем в этом разобраться и однозначно ответить на вопрос о различиях.

Многие задачи, с которыми мы имеем дело при цифровизации производства (неважно какого), – это задачи оптимизации: оптимизация производственного расписания, оптимизация цепочек поставок и размещения объектов, оптимизационное планирование и прочее. Многие из них сводятся к проблемам смешанного линейно-целочисленного типа (MILP – Mixed Integer Linear Problem). Конечно же мы хотим их решать быстрее и эффективнее, поэтому год назад начали разработку ML-модулей для этого. В этой статье мы познакомим вас с концептом одного такого модуля – для упрощения MILP методом обнуления переменных – и расскажем о том, насколько нам удалось с его помощью сократить время работы решателя.

Очевидный для ML-инженера факт: если на вход модели подать мусор — на выходе тоже будет мусор. Это правило действует всегда, независимо от того, насколько у нас крутая модель. Поэтому важно понимать, как ваши данные будут храниться, использоваться, версионироваться и воспроизведутся ли при этом результаты экспериментов. Для всех перечисленных задач есть множество различных инструментов: DVC, MLflow, W&B, ClearML и другие. Git использовать недостаточно, потому что он не был спроектирован под требования ML. Но есть инструмент, который подходит для версионирования данных и не только — это ClearML. О нем я сегодня и расскажу.

В 2024 году ни одна крупная компания в мире, работающая с CAD (BIM) данными, не получает доступ к данным из CAD (BIM) программ через API или плагины.
Все крупные компании, работающие с форматами CAD (BIM), работают с определенными SDK, а форматы, содержащие данные о строительных проектах становятся взаимозаменяемы.










Привет, habr! 👋
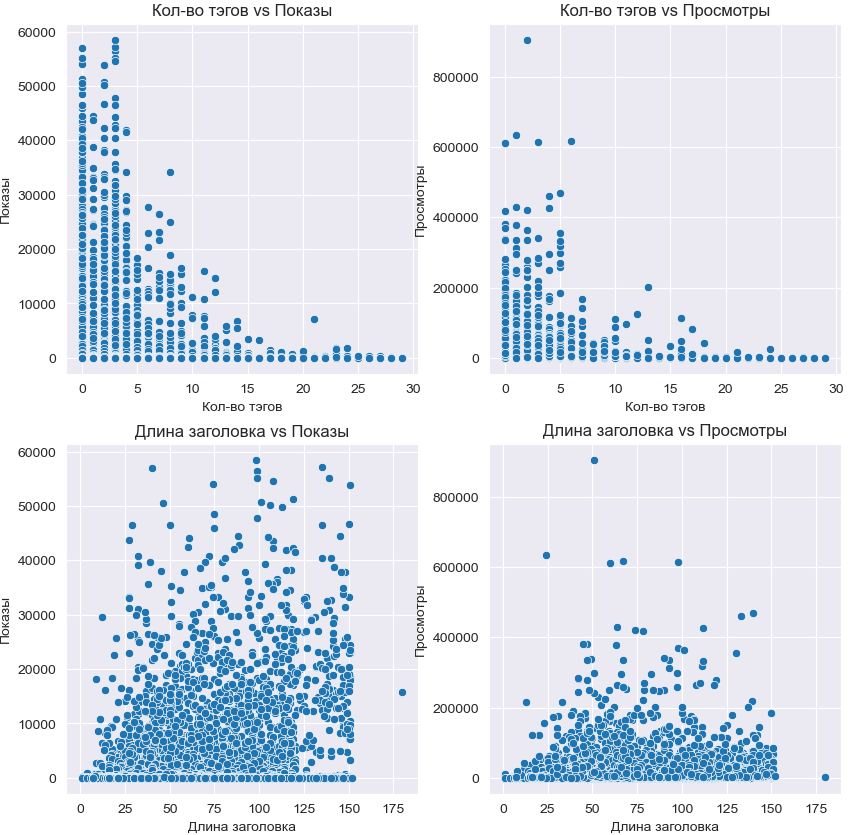
Вы когда-нибудь задумывались, почему некоторые посты набирают тысячи просмотров, а другие остаются незамеченными? Ясно, что Content is King, но есть ли дополнительные факторы, которые влияют на успешность поста?
Мы решили не гадать, а действовать. 🔍
Соскрейпили все посты на VC, а затем посчитали корреляции, чтобы выяснить, что же на самом деле привлекает внимание аудитории.


Приветствую. Речь в статье пойдёт про мой опыт реверсинга и написания ботнета для $NotCoin.
Дело было вечером, делать было нечего, подружка села на заборе — и скинула мне ссылку на ноткоин в альфе.
Посмотрел, потыкал, недолго думая, я забыл про него на месяц.
И вот он уже набрал аудиторию и я подумал, что всё же стоит посмотреть что там да как.
Суть игры в одном слове: кликер.
И что же нужно делать?
— У тебя есть монетка, на неё нужно кликать, чем больше монет - тем лучше.

Привет! Использование ИИ в разметке данных для него же — уже скорее необходимая потребность, нежели что-то удивительно новое. Разного рода экспериментами с авторазметкой данных нейронками мы занимаемся последние полгода и результаты — нравятся.
В данной статье я детально расскажу о нашем самом первом эксперименте с LLM в разметке данных для ИИ и proof-of-concept их годноты использования в реальных задачах, а в процессе попробую ответить на большой вопрос — так заменят ли LLM людей в разметке данных?
Давайте вооружимся GigaChat, chatGPT, Gemini и начнем!

На фоне развития генеративных и больших языковых моделей набирают обороты векторные базы данных. В прошлый раз в блоге beeline cloud мы обсудили, насколько этот тренд устойчив, а также предложили несколько книг для желающих погрузиться в тему. Сегодня же мы собрали компактную подборку открытых СУБД и поисковых движков, способных помочь в разработке систем ИИ. Обсуждаем такие инструменты, как Lantern, LanceDB, CozoDB, ArcadeDB, Dart Vector DB, Marqo и Orama.

Все мы работаем в разных предметных областях, и бывает усложно уделить время знакомству с BI. Надеюсь, у Вас есть менее получаса на чтение этой статьи и знакомство с примером, а также есть желание провести графический BI анализ на .NET, в таком случае - добро пожаловать.
В этой статье мы создадим .NET приложение для визуализации исторических реальных BI данных компании IBM о стоимости акций на нью-йоркской бирже за последние дни, код примера.
С учетом опыта над зарубежными (MercerInsight) и отечественными (Visiology) BI продуктами, а также над оригинальными BI системами для крупных отечественных IT компаний, у меня, честно говоря, сложилось впечатление, что популярным решением для визуализации и чуть ли не стандартом де-факто являются HighCharts. Безусловно, есть альтернативы (даже условно CrystalReports, DevExpress и т.д.), в этой статье будут использованы именно HighCharts, мы увидим их особенности и преимущества. Также для простоты будет просто обычный JS, но обычно в реальных проектах используются HighCharts в связке с одним из TypeScript фронтендным фреймворком.
Создадим новый MVC .NET проект (например, .NET 8) из .NET CLI и добавим dev HTTPS сертификаты:

Представляю вашему вниманию статью, посвященную авторскому алгоритму «Evolution of Social Groups» (ESG) C#. Этот уникальный метод оптимизации, основанный на взаимодействии социальных групп, открывает новые горизонты в области метаэвристики. В статье подробно рассматриваются основные принципы работы алгоритма, его преимущества и области применения. Присоединяйтесь, чтобы узнать больше о мире оптимизации и возможностях, которые он открывает. Поехали…



