
Сказ о том, как с помощью Opuna’ы сделать вашу RAG-систему чуточку (а может и не чуточку) эффективнее :)

Компьютерный анализ и синтез естественных языков
Сказ о том, как с помощью Opuna’ы сделать вашу RAG-систему чуточку (а может и не чуточку) эффективнее :)

Привет, Хабр!
Сегодня мы поговорим о том, какие LLM лучше всего работают на бизнес-задачах. AI-хайп находится на локальном пике, похоже, что весь мир только и делает, что внедряет AI-фичи в свои продукты, собирает миллионы на разработку еще одной оболочки для ChatGPT, заполняет свои ряды AI-тулами и, кажется, предоставляет работу роботам, пока сами попивают кофе в старбаксе.

С.Б. Пшеничников
В статье изложен новый математический аппарат вербальных вычислений в NLP (обработке естественного языка). Слова погружаются не в действительное векторное пространство, а в алгебру предельно разреженных матричных единиц. Вычисления становятся доказательными и прозрачными. На примере показаны развилки в вычислениях, которые остаются незамеченными при использовании традиционных подходов, а результат при этом может быть неожиданным.
Использование IT в обработке естественного языка (Natural Language Processing, NLP) требует стандартизации текстов, например, токенизации или лемматизации. После этого можно пробовать применять математику, поскольку она является высшей формой стандартизации и превращает исследуемые объекты в идеальные, например, таблицы данных в матрицы элементов. Только на языке матриц можно искать общие закономерности данных (чисел и текстов).
Если текст превращается в числа, то в NLP это сначала натуральные числа для нумерации слов, которые затем погружаются в действительное векторное пространство.
Возможно, следует не торопиться это делать, а придумать новый вид чисел более пригодный для NLP, чем числа для исследования физических явлений. Такими являются матричные гипербинарные числа. Гипербинарные числа - один из видов гиперкомплексных чисел.
Для гипербинарных чисел существует своя арифметика и если к ней привыкнуть, то она покажется привычнее и проще пифагорейской арифметики.
В системах поддержки принятия решений (DSS) текстами являются оценочные суждения и пронумерованная шкала вербальных оценок. Далее (как и в NLP) номера превращаются в векторы действительных чисел и используются как наборы коэффициентов средних арифметических взвешенных.

Слова «доклад про AI/ML» могут звучать словно очередной рассказ про будущее, где вкалывают роботы, а не человек. Такое мы все уже слышали сто раз.
Но на нашей онлайн-конференции I'ML всё будет иначе:
— Она рассчитана на тех, кто лично использует ML в проектах.
— Она не о далёком будущем, а о вопросах, актуальных уже здесь и сейчас.
— Она не об абстрактном («было бы здорово…»), а о конкретном: «как бороться с ML-галлюцинациями», «как рекомендовать размер одежды с помощью ML».
— Она не о том, как «нейросети отберут работу», а наоборот: о ML-работе, которую нейросети нам дали.
В общем, она не для желающих просто пофантазировать, а для специалистов, желающих эффективно работать.
А что именно там будет? До конференции остался месяц, и мы представляем Хабру её программу:

Приветствую, хабровчане!
Сегодня пятница, поэтому предлагаю немного пошалить и поговорить о слегка необычном, но весьма забавном проекте обучения нейросетевой модели на базе LLaMA2 7B, которая умеет превращать невинные предложения на русском языке в чуть более "токсичные" их версии.
Но обучать модель мы будем не абы как, а при помощи недавно вышедшего в свет проекта под названием TorchTune, так как надо ведь пробовать новые инструменты, иными словами, предлагаю соединить тему интересную с темой полезной.
Так что пристегнитесь, будет весело и слегка токсично!

В этой статье рассмотрим пять лучших библиотек Python, предназначенных специально для работы с русским языком в контексте NLP. От базовых задач, таких как токенизация и морфологический анализ, до сложных задач обработки и понимания естественного языка.

Обзорное видео с доклада об особенностях обучения LLM для тех, кто в теме ML/DL, но хочет расширить кругозор в области работы с большими языковыми моделями. На основе личного опыта и обзора множества научных статей и инструментов. Ссылка на презентацию прилагается.

Привет, Хабр! Меня зовут Даниил, работаю в ML-отделе Doubletapp. В статье расскажу про особенности применения больших языковых моделей для оптимизации бизнес-процессов.
Большая языковая модель (LLM) — это тип языковой модели, который способен распознавать и генерировать осмысленные тексты, а также другие сложные типы данных (например, код). Такого рода модели обучаются на огромных массивах данных, чаще всего собранных из открытых источников.
Тем не менее LLM все еще имеют ряд проблем, одной из которых является галлюцинирование (придумывание фактов). Сложно винить модель за то, что она не знает, как устроен тот или иной процесс/продукт в вашей компании, и пытается придумать вразумительный ответ. Поэтому нужно подсказать LLM фактическую информацию, а она уже даст нам понятную человеку персонализированную реплику.
Такая система ответов на вопросы с использованием фактической информации называется RAG (Retrieval Augmented Generation).
Данная статья состоит из двух частей:
• мы рассмотрим построение RAG-системы на основе библиотеки langchain;
• объективно оценим работоспособность созданной системы, используя синтетические данные на русском языке с помощью фреймворка RAGAs.

После появления на рынке API для беседы с ChatGPT 3.5 каждый второй заказчик решения на основе машинного обучения (ML) хочет внедрить у себя ИИ, который может красиво и содержательно общаться на русском языке.
Меня зовут Екатерина, я IT-архитектор команды SimbirSoft, специалист по ML и поклонница всего, что связано с обработкой текстов на естественном языке (NLP). Сегодня будем разбираться в тонкостях решения одной из популярных на рынке задач – автоматического составления аннотаций. Для эксперимента мы использовали две GPT-подобных модели, «заточенных» на русский язык: GigaChat и YandexGPT. Заявленный потенциал систем тестировали на текстах трёх жанров: научном, научно-популярном и художественном. Что из этого получилось, расскажем в статье.
Материал будет полезен тем, кто следит за тенденциями развития машинного обучения на рынке и в целом интересуется внедрением больших языковых моделей (LLM) в ML-проектах – для оценки их возможностей «из коробки».

Удаление определенной информации в процессе обучения помогает моделям машинного обучения быстрее и лучше осваивать новые языки.
Группа ученых в области компьютерных наук придумала более гибкую модель машинного обучения. В чем особенность: модель должна периодически забывать кое-что из того, что знает. Новый подход не заменит огромные модели, но зато, возможно, подскажет нам, как именно они понимают естественный язык.

Как я пытался собрать "по-быстрому" локальный RAG(retrieval augmentation generation), который будет находить термины из словаря Ожегова. На просторах интернетах все просто. Но на практике для моей задачи это оказалось не так. Точность...
В последнее время активно разрабатываются технологии экстремально малоразрядного квантования, например, BitNet и 1.58 bit. Они пользуются большим интересом в сообществе машинного обучения. Основная идея данного подхода заключается в том, что перемножение матриц с квантованными весами можно реализовать и умножения, что потенциально полностью меняет правила игры применительно к скорости вычислений и эффективности больших моделей машинного обучения.
Эта статья написана в схожем ключе, но нас наиболее интересует, возможно ли напрямую квантовать предобученные модели при экстремальных настройках, в том числе, при двоичных весах (0 и 1). Уже имеющиеся работы нацелены на обучение моделей с нуля. Но в открытом доступе сейчас достаточно много отличных предобученных моделей, таких как Llama2. Более того, обучение с нуля — это ресурсозатратная задача в пересчёте как на вычисления, так и на данные, поэтому такие подходы не слишком доступны в свободном сообществе.
В этой статье мы подробно разберём крайне малоразрядное (2 и 1-разрядное) квантование предобученных моделей с применением HQQ+. HQQ+ — это адаптация HQQ (полуквадратичного квантования), в которой для повышения производительности используется адаптер с низкой размерностью. Наши результаты показывают, что при обучении лишь небольшой части весов в верхней части HQQ-квантованной модели (даже одноразрядной) качество вывода значительно возрастает, такая модель может даже превосходить небольшие модели полной точности.
Модели находятся на Hugging Face: 1-разрядная, 2-разрядная.
Всем привет, я Григорий Тумаков, CTO в Моризо Диджитал.
Недавно рассказал на Хабре, как мы в компании “потрогали” нейросети для прикладных задач разработки. Но там никаких серьезных выводов сделать не удалось.
Поэтому решил на этом не останавливаться. Если есть инструменты — их надо протестировать на какой-то реальной задаче.
Далее в статье наш опыт сравнения для прикладной задачи трех AI-инструментов: Phind, ChatGPT, Machinet.









В приложении «Магнит: акции и доставка» можно оставлять отзывы на товары. Отзывы модерируются: мы публикуем те, которые считаем полезными для других покупателей, — они должны описывать потребительские свойства товара. Отклоняем все остальные: как правило, это жалобы на ценники, сервис в магазине, условия хранения либо просто нерелевантные тексты. Отзывы с жалобами обрабатывают службы поддержки и сервиса.
Рассказываем о том, как мы попробовали применять большие языковые модели, чтобы автоматизировать модерацию отзывов.
 Привет, Хаброжители!
Привет, Хаброжители!
В октябре прошлого года мы выпустили SAGE — библиотеку для генеративной коррекции орфографии, которая включает в себя семейство предобученных трансформерных моделей, хаб с параллельными вручную размеченными датасетами и два алгоритма текстовой аугментации на основе намеренного искажения правописания.
С момента прошлого релиза мы улучшили качество наших моделей более чем на 10%, добавили правку знаков пунктуации и регистра, провели эксперименты по сжатию и ускорению полученных решений, добавили разметку пунктуации в датасеты и новые метрики в библиотеку, а нашу статью взяли на EACL 2024 в Мальте.

Мы выложили в публичный доступ гигантский датасет для детекции речи (voice activity detection).
Датасет содержит порядка 150 тысяч часов аудио более чем на 6,000 языках. Количество уникальных ISO-кодов данного датасета не совпадает с фактическим количеством языков, так как близкие языки могут кодироваться одним и тем же кодом.
Данные были размечены для задачи детекции голоса при временной дискретизации примерно в 30 миллисекунд (или 512 семплов при частоте дискретизации 16 килогерц).
Данный датасет распространяется под лицензией CC BY-NC-SA 4.0.

В прошлом году на конференции AIJ 2023 мы представили первую версию OmniFusion — мультимодальной языковой модели (LLM), способной поддерживать визуальный диалог и отвечать на вопросы по картинкам. Спустя несколько месяцев мы готовы представить обновление — OmniFusion 1.1 — SoTA на ряде бенчмарков (среди моделей схожего размера) и, более того, модель хорошо справляется со сложными задачами и понимает русский язык! Самое главное — всё выкладываем в открытый доступ: веса и даже код обучения.
Ниже расскажем об особенностях модели, процессе обучения и примерах использования. В первую очередь остановимся на архитектуре, а потом отдельно расскажем о проделанных экспериментах как в части архитектурных трюков, так и о работе с данными. Ну а несколько интересных кейсов на англ и русском языках можно посмотреть на палитре ниже.

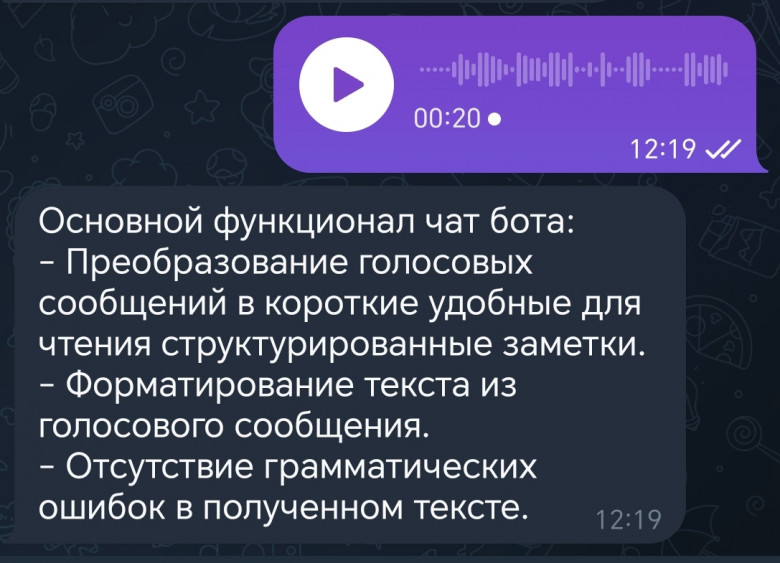
Вы когда-нибудь оказывались в ситуации, когда голова была полна идей, но записать их нет возможности? Тогда вы знаете, как бывает сложно быстро и качественно зафиксировать свои мысли. А может вам знакома ситуация, когда собеседник записывает голосовое сообщение на 5 минут с описанием какого-нибудь проекта, и вам приходится переслушивать его снова и снова, чтобы понять все детали. Столкнувшись с этим, я решил сделать Telegram-бота, который может превратить голосовое сообщение в структурированную заметку.



