Привет, меня зовут Наталья, я работаю в Яндексе разработчиком в группе извлечения фактов. Весной мы рассказали о том, что такое Томита-парсер и для чего он используется в Яндексе. А уже этой осенью исходники парсера будут выложены в открытый доступ.
В предыдущем посте мы пообещали рассказать, как пользоваться парсером и о синтаксисе его внутреннего языка. Именно этому и посвящен мой сегодняшний рассказ.

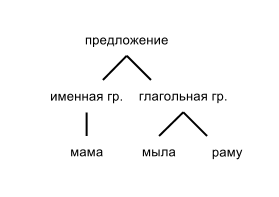
Прочитав этот пост, вы узнаете, как составляются словари и грамматики для Томиты, а также, как извлекать с их помощью факты из текстов на естественном языке. Та же информация доступна в формате небольшого видеокурса.