

Библиотека dplyr в R позволяет манипулировать данными, проводить фильтрацию, выборку, сортировку, группировку данных и многое другое.
В этой статье как раз и рассмотрим эту библиотеку.
Библиотека dplyr в R позволяет манипулировать данными, проводить фильтрацию, выборку, сортировку, группировку данных и многое другое.
В этой статье как раз и рассмотрим эту библиотеку.

Небольшой эксперимент по применению LLM при решении задач анализа данных на R и краткие выводы по нему.
По работе стояла задача оптимизации поиска по адресам (улицы, дома и объекты). Главный критерий - нахождение адреса, если написано с ошибками или не дописан он в полной мере. Bert’ы, косинусные расстояния эмбеддингов и т.д. не подходили, так как они заточены под смысловой поиск, а в адресах смысла нет. TF-IDF c лемматизацией тоже не очень подходил для этой задачи, результаты были плохие.
Для реализации начал использовать расстояние Дамерау-Левенштейна, и в последствие, развил это до собственного алгоритма, который находит расстояние между двумя строками.
Цель данного поста описание только алгоритма.

В статье расскажу поподробнее про оценку локаций для бизнеса.
Проблема классическая: ищем место для открытия нового магазина/ресторана/пиццерии.
Сразу скажу, что при помощи гео я решал очень узкий набор задач:
• Оценить существующие локации с т.з. плотности населения, конкуренции, объема рынка. Найти новые точки для открытия или переезда бизнеса;
• Использовать признаки близости покупателя к бизнесу/конкурентам в клиентской аналитике для предсказаний оттока и откликов на рассылки/оффлайн рекламу;
Сегодня расскажу поподробнее про оценку локаций. Все работы я производил на языке R.

Всем доброго дня!
Некоторое время назад нами была написана обзорная статья о методах анализа данных, используемых при разработке инновационных лекарств, и теперь пришло время поподробнее остановиться на отдельных пунктах этой публикации.
Сегодня мы поговорим о таком подходе как анализ выживаемости (survival analysis) или, как его еще называют, анализ времени до наступления события (time-to-event analysis, ТТЕ). Звучит немного зловеще; и действительно: лично я познакомилась с этой методикой, занимаясь оценкой эффекта различных видов терапии на выживаемость пациентов с онкологическими заболеваниями. Забегая вперед, скажу, что сфера применения ТТЕ значительно шире, поэтому ее понимание может пригодиться широкому кругу специалистов. Данная статья освящает наиболее базовые концепции TTE, однако в конце искушенный читатель найдет список более исчерпывающих трудов.

Drake предлагает систематический подход к построению и управлению зависимостями в проектах, автоматизируя процесс обработки данных и анализа. С помощью drake можно отслеживать изменения в коде и данных, автоматически перезапуская только те части анализа, которые были изменены.
Создатель drake, Уилл Ландау, искал способ улучшить репродуктивность исследований в R, и так родилась библиотека drake. С тех пор она претерпела множество изменений и улучшений.

Приветствую!
Stan - это библиотека на C++, предназначенная для байесовского моделирования и вывода. Она использует сэмплер NUTS, чтобы создавать апостериорные симуляции модели, основываясь на заданных пользователем моделях и данных. Так же Stan может использовать алгоритм оптимизации LBFGS для максимизации целевой функции, к примеру как логарифмическое правдоподобие.
Для облегчения работы с Stan из языка программирования R доступен пакет rstan, который предоставляет интерфейс R для Stan.
Сегодня мы и рассмотрим этот пакет.

Привет, Хабр!
Параллельные вычисления – подход к проектированию и выполнению программ, который позволяет ускорить обработку данных и вычисления, используя множество процессоров или ядер процессора одновременно.
В ЯП R паралельное выполнение также имеет свои варианты реализации. Рассмотрим их в статье.
Возьмем пример: Как создать бота в Telegram
Если вы когда нибудь читали документацию Яндекс облака, вы в курсе. Для остальных могу пояснить. Возьмите лапидарный текст, удалите из него ясность и чёткость и вы получите документацию Яндекс облака.
В статье я хочу поделиться теми моментами которые всплыли при разработке бота в телеграм, но не описаны в документации.
В первой части говорили про использование поиска и генерации ответа с помощью языковых моделей. В этой части рассмотрим память и агентов.
Для этой задачи использую LLM (Large Language Models - например, chatGPT или opensouce модели) для внутренних задач (а-ля поиск или вопрос-ответную систему по необходимым данным).
Я пишу на языке R и также увлекаюсь NLP (надеюсь, я не один такой). Но есть сложности из-за того, что основной язык для LLM - это python. Соответственно, на R мало примеров и документации, поэтому приходится больше времени тратить, чтобы “переводить” с питона, но с другой стороны прокачиваюсь от этого.
Чтобы не городить свою инфраструктуру, есть уже готовые решения, чтобы быстро и удобно подключить и использовать. Это LangChain и LlamaIndex. Я обычно использую LangChain (дальше он и будет использоваться). Не могу сказать, что лучше, просто так повелось, что использую первое. Они написаны на питоне, но с помощью библиотеки reticulate всё работает и на R.

Привет, Хабр!
В этой статье рассмотрим план становления начинающим дата-сайнтистом. Рассмотрим, что и где изучать, чтобы преисполниться в своём познании. А там и до оффера недалеко

Гибадуллина Д.А Гибадуллина Дарья Анатольевна/ Gibadullina Daria Anatolievna- студент второго курса бакалавриат Уральского филиала Финансового университета направления бизнес-информатика
Аннотация: Язык программирования R имеет широкое применение в области статистических вычислений и анализа данных В данной статье мы рассмотрим основные возможности языка R, его синтаксис и особенности, а также примеры использования для решения задач статистического анализа данных. Также мы рассмотрим некоторые популярные пакеты и библиотеки, которые доступны для работы с данными в R. Данная статья поможет читателю ознакомиться с основами языка R и его применением в статистических вычислениях.
Annotation: The R programming language has wide application in the field of statistical computing and data analysis. In this article, we will consider the main features of the R language, its syntax and features, as well as examples of use for solving problems of statistical data analysis. We will also look at some popular packages and libraries that are available for working with data in R. This article will help the reader to familiarize himself with the basics of the R language and its application in statistical computing.
Ключевые слова: язык программирования, язык программирования R, синтаксис R, библиотеки R, анализ данных, статистический анализ, обработка данных на R.
Keywords: programming language, R programming language, R syntax, R libraries, data analysis, statistical analysis, data processing in R.








Привет, Хабр!
Сегодня мы поговорим о временных рядах, и как мы можем работать с ними, используя ЯП R. Временные ряды позволяют понять динамику процессов, изменяющихся со временем, и предсказывать тенденции.

Для начала определим для кого эта статья? Моя цель заинтересовать не только обыкновенных зрителей, но и тех, кто уже занимается футбольной аналитикой. В статье я постараюсь показать интересные исследования об Xg.
Многие из тех, кто смотрит футбол и читает новости когда-нибудь видел метрику «xg». Что она вообще означает? Простыми словами Xg это количество ожидаемых голов. Т.е. каждый нанесённый удар по воротам имеет вероятность конвертироваться в забитый мяч, но с каждой позиции эта вероятность разная (если углубляться, то станет очевидным, что xg зависит от нескольких параметров, а не от одной позиции). К примеру, самая высокая вероятность забить мяч при исполнении пенальти. Чаще всего с пенальти дают 0.79 xg. Необходимо учитывать, что единой формулы расчёта xg нет, каждый провайдер рассчитывает её по-своему. Так например, для написания этой статьи я использовал данные с сайта https://understat.com/, но, если мы посмотрим другие источники, цифры будут отличаться.
Моя задача узнать, насколько точно Xg предсказывает количество голов в матче. Исследование будем проводить для АПЛ сезона 2022/2023. В данном исследовании мы ограничимся простыми методами анализа. Я составил таблицу из 380 матчей АПЛ.

В заметке кратко описан функционал пакета gMWT, который реализовывает обобщенный тест Манна-Уитни. Описано его применение для проверки гипотез о равенстве законов распределения для случая двух и трех выборок, продемонстрировано его применение для проверки гипотез о принадлежности изучаемого распределения некоторому закону.
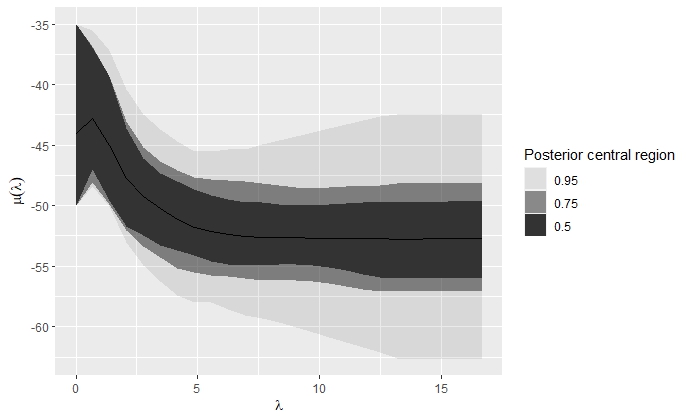
В заметке рассказывается о функционале достаточно простого пакета familial, реализующего весьма оригинальную идею о проверке статистических гипотез, связанных с семейством центральных параметров. Концепция данного семейства была изначально разработана Питером Хубертом в статье «Robust estimation of a location parameter».
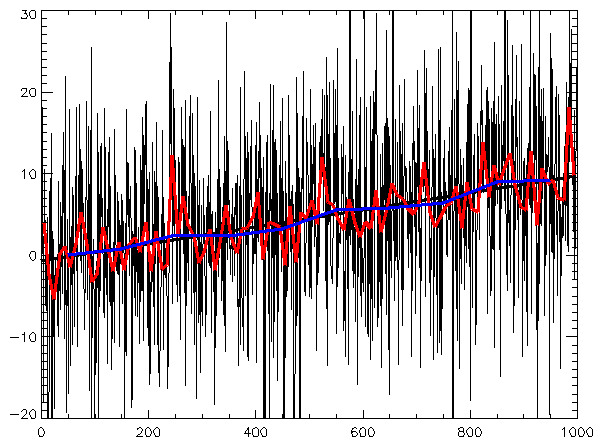
Не буду вдаваться в подробности о том, откуда берутся миллионы временных серий и почему они умудряются изменяться еженедельно. Просто возникла задача еженедельно сделать прогноз на 2-8 недель по паре миллионов временных серий. Причем не просто прогноз, а с кроссвалидацией и выбором наиболее оптимальной модели (ARIMA, нейронная сеть, и т.п.).
Имеется свыше терабайта исходных данных и достаточно сложные алгоритмы трансформации и чистки данных. Чтобы не гонять большие массивы данных по сети решено было реализовать прототип на одном сервере.

Современный мир насыщен данными, анализ информации становится критически важным инструментом для принятия обоснованных решений. Однако просто иметь данные не достаточно – необходимо извлечь из них ценную информацию. В этом процессе статистические тесты и проверка гипотез играют важнейшую роль. Они позволяют нам сделать выводы на основе данных, опираясь на строгие методы анализа, и тем самым способствуют принятию обоснованных решений.
Статистические тесты – это мощный инструмент, который позволяет провести объективную оценку данных и проверить гипотезы, основанные на этой информации. Они позволяют определить, насколько вероятно, что наблюдаемые различия или закономерности случайны, а не реально существующие в популяции. Статистические тесты позволяют избежать ошибок и предоставляют научно обоснованный подход к анализу данных.

Биом Уиттекера, также известный как метод классификации экосистем, делит экосистемы на поверхности земли на различные типы на основе таких факторов, как географическое распределение и условия окружающей среды.Этот метод классификации был предложен американским экологом Робертом Уиттакером (Robert Whittaker) в 1962 году, целью которого является улучшение понятий и описаний разнообразия и функций экосистем. Уиттакер использует два фактора для классификации биологических сообществ: осадки и температуру.