Во второй части статьи рассказывалось о механизмах обнаружения ошибок в процессе обработки.
Обработка завершилась с ошибкой, что делать дальше? Вполне возможно, что потеряна связь с одним из узлов кластера или временно недоступна база данных. В этом случае, нельзя с уверенностью сказать, какие операции выполнились успешно, а какие — нет. Если все операции в цепочке повторно применимы (идемпотентны), например установка флага, то можно просто перезапустить обработку. Если нет, то на помощь приходят механизмы транзакций Storm.
Обработка завершилась с ошибкой, что делать дальше? Вполне возможно, что потеряна связь с одним из узлов кластера или временно недоступна база данных. В этом случае, нельзя с уверенностью сказать, какие операции выполнились успешно, а какие — нет. Если все операции в цепочке повторно применимы (идемпотентны), например установка флага, то можно просто перезапустить обработку. Если нет, то на помощь приходят механизмы транзакций Storm.

























 NUMA (Non-Uniform Memory Access — «Неравномерный доступ к памяти» или Non-Uniform Memory Architecture — «Архитектура с неравномерной памятью») — технология совсем не новая. Я бы даже сказала, что совсем старая. То есть, в терминах музыкальных инструментов, это уже даже не баян, а, скорее,
NUMA (Non-Uniform Memory Access — «Неравномерный доступ к памяти» или Non-Uniform Memory Architecture — «Архитектура с неравномерной памятью») — технология совсем не новая. Я бы даже сказала, что совсем старая. То есть, в терминах музыкальных инструментов, это уже даже не баян, а, скорее,  Я поделюсь 30 практиками для достижения максимальной производительности приложений, которые этого требуют. Затем, я расскажу, как применил их для коммерческого продукта и добился небывалых результатов!
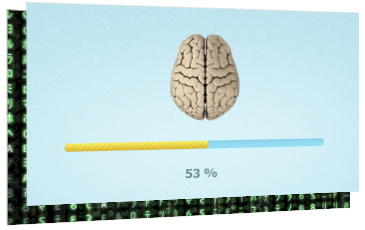
Я поделюсь 30 практиками для достижения максимальной производительности приложений, которые этого требуют. Затем, я расскажу, как применил их для коммерческого продукта и добился небывалых результатов!