
Раньше я описывал небольшой алгоритм, который делал небольшие операции на бинарными деревьями. Я хотел протестировать его. Я попробовал несколько небольших тестов и они прошли, но я не был доволен. Я был почти уверен, но возможно какая-то непонятная топология бинарного дерева могла привести к ошибке. Я сообразил, что существует конечное количество бинарных деревьев данного размера. Я решил попробовать их все.
Алгоритмы поиска старшего бита
3 мин
Здесь я хочу рассказать и обсудить несколько алгоритмов для нахождения старшего единичного бита числа.
На всякий случай, поясню: старшим битом называется единичный бит числа, отвечающий за самую большую степень двойки. Иными словами, это самая большая степень двойки, не превосходящая числа. Чтобы избежать многих случаев, будем здесь считать, что мы имеем дело с натуральным числом в пределах от 1 до 2^31 — 1 включительно. Кроме того, чтобы не слишком углубляться в теорию вероятности, будем считать, что число, в котором требуется определить старший бит, с одинаковой вероятностью будет любым из возможных чисел.
Для начала, рассмотрим самый простой, первым приходящий в голову алгоритм. Давайте переберём все степени двойки, и выберем из них максимальную, которая не превосходит числа. Здесь, очевидно, можно воспользоваться монотонностью этого свойства, то есть тем, что если какая-то степень двойки не превосходит числа, то и меньше степени и подавно не превосходят. Поэтому, это метод можно написать очень просто:
На всякий случай, поясню: старшим битом называется единичный бит числа, отвечающий за самую большую степень двойки. Иными словами, это самая большая степень двойки, не превосходящая числа. Чтобы избежать многих случаев, будем здесь считать, что мы имеем дело с натуральным числом в пределах от 1 до 2^31 — 1 включительно. Кроме того, чтобы не слишком углубляться в теорию вероятности, будем считать, что число, в котором требуется определить старший бит, с одинаковой вероятностью будет любым из возможных чисел.
Для начала, рассмотрим самый простой, первым приходящий в голову алгоритм. Давайте переберём все степени двойки, и выберем из них максимальную, которая не превосходит числа. Здесь, очевидно, можно воспользоваться монотонностью этого свойства, то есть тем, что если какая-то степень двойки не превосходит числа, то и меньше степени и подавно не превосходят. Поэтому, это метод можно написать очень просто:
int bit1(int x) {
int t = 1 << 30;
while (x < t) t >>= 1;
return t;
}
Квадрарный поиск
2 мин
Тернарный (или троичный) поиск — это алгоритм поиска минимума (или максимума) выпуклой функции на отрезке. Можно искать минимум (максимум) функции от вещественного аргумента, можно минимум (максимум) на массиве. Будем, для определённости, искать минимум функции f(x).
Он многим знаком, а для тех, кто не знает, расскажу вкратце.
Тернарный поиск заключается в следующем. Пусть есть рекурсивная функция search(L, R), которая по двум концам отрезка L, R определяет минимум на орезке [L, R]. Если R — L < eps, то мы уже вычислили точку, где достигается минимум, с точностью eps. Иначе, разделим отрезок [L,R] на три равных по длине отрезка [L, A], [A, B] и [B, R]. Сравним значение в точках А и В. Вспомнив, что функция f выпуклая, можно сделать вывод, что если f(A) > f(B), то минимум лежит на отрезке [A,R]. Иначе — на отрезке [L, B]. В соответсвии с этим, можно рекурсивно запуститься от одного из отрезков [L, B] или [A, R]. Каждый раз длина области поиска уменьшается в полтора раза, значит, минимум на отрезке длины X с точностью eps будет найден за время O(log(X/eps)).
А здесь я хочу рассказать о квадрарном (или четверичном) поиске.
Он многим знаком, а для тех, кто не знает, расскажу вкратце.
Тернарный поиск заключается в следующем. Пусть есть рекурсивная функция search(L, R), которая по двум концам отрезка L, R определяет минимум на орезке [L, R]. Если R — L < eps, то мы уже вычислили точку, где достигается минимум, с точностью eps. Иначе, разделим отрезок [L,R] на три равных по длине отрезка [L, A], [A, B] и [B, R]. Сравним значение в точках А и В. Вспомнив, что функция f выпуклая, можно сделать вывод, что если f(A) > f(B), то минимум лежит на отрезке [A,R]. Иначе — на отрезке [L, B]. В соответсвии с этим, можно рекурсивно запуститься от одного из отрезков [L, B] или [A, R]. Каждый раз длина области поиска уменьшается в полтора раза, значит, минимум на отрезке длины X с точностью eps будет найден за время O(log(X/eps)).
А здесь я хочу рассказать о квадрарном (или четверичном) поиске.
Как же все-таки правильно написать двоичный поиск?
2 мин
В обсуждениях статьи Только 10% программистов способны написать двоичный поиск так никто и не написал, как же правильно подойти к решению этой задачи.
Если мы не хотим использовать циклический метод «гадание, затем тестирование, затем исправление ошибок», то без инварианта цикла здесь не обойтись.
Инвариант цикла – это соотношение, которое истинно перед циклом, истинно в процессе выполнения цикла и истинно при выходе из цикла. Все это описано у Дейкстры в книге «Дисциплина программирования», и детально разжевано у Гриса в книге «Наука программирования». Тем не менее, по моим наблюдениям, на практике этот метод практически НИКТО не использует, считая, что все это к реальности не имеет никакого отношения. Это большая ошибка.
Если мы не хотим использовать циклический метод «гадание, затем тестирование, затем исправление ошибок», то без инварианта цикла здесь не обойтись.
Инвариант цикла – это соотношение, которое истинно перед циклом, истинно в процессе выполнения цикла и истинно при выходе из цикла. Все это описано у Дейкстры в книге «Дисциплина программирования», и детально разжевано у Гриса в книге «Наука программирования». Тем не менее, по моим наблюдениям, на практике этот метод практически НИКТО не использует, считая, что все это к реальности не имеет никакого отношения. Это большая ошибка.
Только 10% программистов способны написать двоичный поиск
2 мин
Дональд Кнут (известный тем, что его книги никто не читает) пишет, что хотя первый двоичный поиск был опубликован в 1946 году, первый двоичный поиск без багов был опубликован только в 1962.
Алгоритм двоичного поиска похож на то, как мы ищем слово в словаре. Открываем словарь посередине, смотрим в какой из половин будет нужное нам слово. Допустим, в первой. Открываем первую часть посередине, продолжаем половинить, пока не найдем нужное слово.
С массивами так: есть упорядоченный массив, берем число из середины массива, сравниваем с искомым. Если оно оказалось больше, значит искомое число в первой половине массива, если меньше — во второй. Продолжаем делить оставшуюся половину, когда находим нужное число возвращаем его индекс, если не находим возвращаем null.
Алгоритм двоичного поиска похож на то, как мы ищем слово в словаре. Открываем словарь посередине, смотрим в какой из половин будет нужное нам слово. Допустим, в первой. Открываем первую часть посередине, продолжаем половинить, пока не найдем нужное слово.
С массивами так: есть упорядоченный массив, берем число из середины массива, сравниваем с искомым. Если оно оказалось больше, значит искомое число в первой половине массива, если меньше — во второй. Продолжаем делить оставшуюся половину, когда находим нужное число возвращаем его индекс, если не находим возвращаем null.
Волшебное решето Эратосфена
4 мин

Наверняка все, кто читает этот пост не раз использовали, или хотя бы слышали о решете Эратосфена — методе отыскания простых чисел. Сама проблема получения простых чисел занимает ключевое место в математике, на ней основаны некоторые криптографические алгоритмы, например RSA. Есть довольно много подходов к данной задаче, но в этой статье я остановлюсь на некоторых модификациях самого простого из них — решета Эратосфена.
SGVsbG8gd29ybGQh или история base64
3 мин
Краткая предыстория
Вообще, все началось давно. Настолько давно, что вряд ли остались свидетели holy wars тех дней, когда решалось — сколько же бит должно быть в байте.
Это сейчас нам кажется само собой разумеющимся, что 1 байт = 8 бит, что в байте можно закодировать 256 различных значений. Но когда-то было совсем не так. История помнит и семибитные кодировки, и шестибитные, и даже более экзотические системы (например — ЭВМ «Сетунь», которая использовала троичную логику, то есть один троичный бит — трит мог иметь три, а не два значения, для нее было справедливо соотношение 1 трайт = 6 тритам). Но если оставить в стороне всякую экзотику, то мэйнстримом все-таки были кодировки, в которых 6, 7 или 8 бит в байте.
Шестибитная кодировка (например — BCD) позволяла закодировать в одном байте 64 различных значения, что, как казалось, было вполне достаточно для кодирования алфавитно-цифровых символов, а «лишний» седьмой бит расширял кодировку уже до 128 символов.
Однако скоро восьмибитный байт стал общепринятым.
Классика оптимизации: задача рюкзака (knapsack problem)
3 мин
Рассмотрим следующую ситуацию. Допустим вы хотите поехать за границу, но валюту вам не меняют — вы можете перевезти с собой лишь товары для реализации на свободном рынке «там». С собой в самолет разрешено взять не более 20 кг. Возникает вопрос – какие товары взять, чтобы перевезти максимальную ценность, учитывая ограничение по весу? Водку (17$ / 1,5 кг), большую матрешку (30$ / 2,5 кг), балалайки (75$ / 6 кг) или еще что-то и в каких количествах?
Time-memory trade off и нерадужные таблицы
5 мин
Нет, я не буду рассказывать с какими параметрами нужно генерировать радужные таблицы, или как придумывать «стойкие» пароли. Сама по себе тематика немного устарела и едва ли поможет в отвлеченных вопросах. Но, как оказалось, в основу «радужных таблиц» положен замечательный способ (я бы не стал называть его методом или алгоритмом) размена времени на память, то бишь «time-memory trade off». Это не первый (и, наверное, не последний) топик про предвычисления, но, надеюсь, он Вам понравится.
Теория и практика игры «Морской бой» — по-честному
3 мин
Читая в очередной раз Хабр, я заинтересовался статьей «Морской бой с искусственным интеллектом — по-честному» и программой «Интеллектуальный морской бой».
Попробовав сыграть с ней, я обнаружил, что стратегия программы пока оставляет желать лучшего, т.к. счет был 9:1 в мою пользу.
Я решил поделиться своими мыслями со всеми, и в частности с автором(michurin) программы, т.к. проект очень интересный.
Внимание!
После прочтения данной статьи исход игры «Морской бой» перестанет быть для вас случайностью.
Статья писалась простым языком без использования формул.
«Любая формула, включенная в книгу, уменьшает число ее покупателей вдвое» Стивен Хокинг.
Попробовав сыграть с ней, я обнаружил, что стратегия программы пока оставляет желать лучшего, т.к. счет был 9:1 в мою пользу.
Я решил поделиться своими мыслями со всеми, и в частности с автором(michurin) программы, т.к. проект очень интересный.
Внимание!
После прочтения данной статьи исход игры «Морской бой» перестанет быть для вас случайностью.
Статья писалась простым языком без использования формул.
«Любая формула, включенная в книгу, уменьшает число ее покупателей вдвое» Стивен Хокинг.
Эффективная сегментация изображений на графах
10 мин

Сегментация изображений и выделение границ объектов (edge detection) играют важную роль в системах Computer Vision и применяются для задач распознавания сцен и выделения (определения) объектов. По большому счету, это такой же инструмент, как, например, сортировка, предназначенный для решения более высокоуровневых задач. И поэтому понимание устройства данного класса алгоритмов не будет лишним при построении подобных систем с учетом предъявляемых требований (в плане качество/производительность) и специфики поставленных задач.
В данной статье кратко описан алгоритм «Efficient Graph-Based Image Segmentation» авторов Pedro F. Felzenszwalb (MIT) и Daniel P. Huttenlocher (Cornell University), опубликованный в 2004 году. Да, алгоритм относительно старенький, но, несмотря на это, он до сих пор остается весьма популярным, демонстрируя неплохие результаты в плане производительности.
Под катом – большая смесь картинок и текста, не требовательная к текущему уровню знаний тематики. Любопытство приветствуется.
Асимптотический анализ алгоритмов
7 мин
Прежде чем приступать к обзору асимптотического анализа алгоритмов, хочу сказать пару слов о том, в каких случаях написанное здесь будет актуальным. Наверное многие программисты читая эти строки, думают про себя о том, что они всю жизнь прекрасно обходились без всего этого и конечно же в этих словах есть доля правды, но если встанет вопрос о доказательстве эффективности или наоборот неэффективности какого-либо кода, то без формального анализа уже не обойтись, а в серьезных проектах, такая потребность возникает регулярно.
В этой статье я попытаюсь простым и понятным языком объяснить, что же такое сложность алгоритмов и асимптотический анализ, а также возможности применения этого инструмента, для написания собственного эффективного кода. Конечно, в одном коротком посте не возможно охватить полностью такую обширную тему даже на поверхностном уровне, которого я стремился придерживаться, поэтому если то, что здесь написано вам понравится, я с удовольствием продолжу публикации на эту тему.
В этой статье я попытаюсь простым и понятным языком объяснить, что же такое сложность алгоритмов и асимптотический анализ, а также возможности применения этого инструмента, для написания собственного эффективного кода. Конечно, в одном коротком посте не возможно охватить полностью такую обширную тему даже на поверхностном уровне, которого я стремился придерживаться, поэтому если то, что здесь написано вам понравится, я с удовольствием продолжу публикации на эту тему.
Ближайшие события












Firebird Conf: конференция для разработчиков и администраторов СУБД Firebird
6 июня
09:00 – 20:00
Москва


Algorithmatic — социальный ресурс алгоритмов
1 мин

Открылся новый ресурс посвященный различным алгоритмам и их реализации. Выделяется Algorithmatic среди прочих несколькими особенностями: во-первых, ресурс наполняется самими пользователями, то есть является социальным, а во-вторых, кроме исходного кода алгоритма на сайте влючена возможность отладки кода.
Map/Reduce: решение реальных задач — TF-IDF — 2
3 мин
Продолжая статью “Использование Hadoop для решения реальных задач”, хочу напомнить, что в прошлой статье мы остановились на том, что посчитали такую характеристику как tf(t,d), и сказали, что в следующем посте мы будем считать idf(t) и завершим процесс вычисления значения TF-IDF для данного документа и термина. Поэтому предлагаю долго не откладывать и переходить к этой задаче.
Важно заметить, что idf(t) не зависит от документа, потому как считается на всем корпусе. Это нетрудно увидеть, посмотрев на формулу:
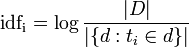
Вероятно, она нуждается в некоторых пояснениях. Итак, |D| это мощность корпуса документов — иными словами, просто количество документов. Мы знаем его, поэтому считать ничего не надо. Знаменатель же логарифма — это количество таких документов d которые содержат интересующий нас токен t_i.
Важно заметить, что idf(t) не зависит от документа, потому как считается на всем корпусе. Это нетрудно увидеть, посмотрев на формулу:
Вероятно, она нуждается в некоторых пояснениях. Итак, |D| это мощность корпуса документов — иными словами, просто количество документов. Мы знаем его, поэтому считать ничего не надо. Знаменатель же логарифма — это количество таких документов d которые содержат интересующий нас токен t_i.
Map/Reduce: решение реальных задач — TF-IDF
6 мин
Вчера я задал вопрос в своем ХабраБлоге — интересно ли людям узнать, что такое Hadoop с точки зрения его реального применения? Оказалось, интересно. Дело недолгое — статью я написал довольно быстро (по крайней мере, ее первую часть) — как минимум, потому, что уже давно знал, о чем собираюсь написать (потому как еще неплохо помню как я сам тыкался в поиске информации, когда начинал пользоваться Hadoop). В первой статье речь пойдет об основах — но совсем не о тех, про которые обычно рассказывают :-)
Перед прочтением статьи я настоятельно рекомендую изучить как минимум первый и последний источники из списка для чтения — их понимание или хотя бы прочтение практически гарантирует, что статья будет понята без проблем. Ну что, поехали?

Ну скажите, какой смысл об этом писать? Уже не раз это проговаривалось, неоднократно начинали писаться посты на тему Hadoop, HDFS и прочая. К сожалению, обычно все заканчивалось на довольно пространном введении и фразе “Продолжение следует”. Так вот: это — продолжение. Кому-то тема, затрагиваемая в этой статье может показаться совершенно тривиальной и неинтересной, однако же лиха беда начало — любые сложные задачи надо решать по частям. Это утверждение, в частности, мы и реализуем в ходе статьи. Сразу замечу, что я постараюсь избежать написания кода в рамках этой конкретной статьи — это может подождать, а понять принципы построения программ, работающих с Map/Reduce можно и “на кошках” (к тому же с текущей частотой кардинального изменения API Hadoop любой код становится obsolete примерно через месяц).
Когда я начинал разбираться с Хадупом, очень большой сложностью лично для меня стало первоначальное понимание идеологии Map/Reduce (я предпочитаю писать это словосочетание именно так, чтобы подчеркнуть, что речь идет не о продукте, а о принципе). Суть и ценность метода станет понятна в самом конце — после того, как мы решим несложную задачу.
Перед прочтением статьи я настоятельно рекомендую изучить как минимум первый и последний источники из списка для чтения — их понимание или хотя бы прочтение практически гарантирует, что статья будет понята без проблем. Ну что, поехали?
Что такое Hadoop?
Ну скажите, какой смысл об этом писать? Уже не раз это проговаривалось, неоднократно начинали писаться посты на тему Hadoop, HDFS и прочая. К сожалению, обычно все заканчивалось на довольно пространном введении и фразе “Продолжение следует”. Так вот: это — продолжение. Кому-то тема, затрагиваемая в этой статье может показаться совершенно тривиальной и неинтересной, однако же лиха беда начало — любые сложные задачи надо решать по частям. Это утверждение, в частности, мы и реализуем в ходе статьи. Сразу замечу, что я постараюсь избежать написания кода в рамках этой конкретной статьи — это может подождать, а понять принципы построения программ, работающих с Map/Reduce можно и “на кошках” (к тому же с текущей частотой кардинального изменения API Hadoop любой код становится obsolete примерно через месяц).
Когда я начинал разбираться с Хадупом, очень большой сложностью лично для меня стало первоначальное понимание идеологии Map/Reduce (я предпочитаю писать это словосочетание именно так, чтобы подчеркнуть, что речь идет не о продукте, а о принципе). Суть и ценность метода станет понятна в самом конце — после того, как мы решим несложную задачу.
Пузырьки, кэши и предсказатели переходов
6 мин
Эта заметка написана по мотивам одного любопытного поста, краткий коммент её же автора к которому сподвиг меня разобраться в происходящем поподробнее. Предлагается сравнить две вариации алгоритма сортировки пузырьком. Первая из них – обычный пузырёк, с небольшой оптимизацией — внутренний цикл можно закончить немного раньше, зная, что оставшаяся часть массива уже отсортирована:
Во втором варианте внутренний цикл проходит по другой части массива, однако алгоритмически этот вариант эквивалентен первому (подробности ниже):
Запускаем (код), например, для N=100 000 на массиве int'ов, и получаем около 30 секунд в первом случае, и меньше 10 секунд — во втором, то есть отличие в 3 раза! Откуда же тогда берётся такая разница?
for (i=0; i<N; i++)
for (j=0; j<N - (i+1); j++)
if (a[j] > a[j+1])
swap(a[j], a[j+1]);Во втором варианте внутренний цикл проходит по другой части массива, однако алгоритмически этот вариант эквивалентен первому (подробности ниже):
for (i=0; i<N-1; i++)
for (j=i; j>=0; j--)
if (a[j] > a[j+1])
swap(a[j], a[j+1]);Запускаем (код), например, для N=100 000 на массиве int'ов, и получаем около 30 секунд в первом случае, и меньше 10 секунд — во втором, то есть отличие в 3 раза! Откуда же тогда берётся такая разница?
Генерация музыки на основе заданного стиля
14 мин
 |
В данном посте я хочу рассказать об очень простом способе генерации музыки в заданном стиле с помощью контекстно-зависимой грамматики. |
dual-pivot quicksort
1 мин
Улучшенный алгоритм quicksort: iaroslavski.narod.ru/quicksort/DualPivotQuicksort.pdf
Краткое описание:
Обычный quicksort делит массив на два отрезка, выбрав случайный элемент P. Потом сортирует массив так, чтобы все элементы меньше P попали в первый отрезок, а остальные — во второй. Затем алгоритм рекурсивно повторяется на первом и на втором отрезках.
Dual-pivot quicksort делит массив на три отрезка, вместо двух. В результате количество операций перемещения элементов массива существенно сокращается.
В PDF-е автор алгоритма привдит более детализированное описание алгоритма и имплементацию на java.
Краткое описание:
Обычный quicksort делит массив на два отрезка, выбрав случайный элемент P. Потом сортирует массив так, чтобы все элементы меньше P попали в первый отрезок, а остальные — во второй. Затем алгоритм рекурсивно повторяется на первом и на втором отрезках.
Dual-pivot quicksort делит массив на три отрезка, вместо двух. В результате количество операций перемещения элементов массива существенно сокращается.
В PDF-е автор алгоритма привдит более детализированное описание алгоритма и имплементацию на java.
Найти соседей на Google Maps
2 мин
Посмотрел статистику посещения сайта Кафе Ульяновска и понял, что порядка 30% посетителей приходят к нам через поисковик на страницу с конкретным описанием кафешки, получают нужную информацию и уходят восвояси.
«Непорядок» решили мы и поставили новую задачу — отображать на странице кафешки ближайшие заведения.
«Непорядок» решили мы и поставили новую задачу — отображать на странице кафешки ближайшие заведения.