Скорее всего, вы поняли заголовок правильно, хотя в нём есть стилистическая ошибка — двусмысленность (кто-то учит LLM, или они учат кого-то?).
Человеческое понимание языка остается ориентиром и пока недостижимой целью для языковых моделей. При всей небезошибочности первого и при всех невероятных успехах последних. Например, человеку обычно не составляет труда однозначно трактовать двусмысленные фразы исходя из контекста. Более того, мы с удовольствием используем такие каламбуры в шутках разного качества. Из самого известного приходит на ум только “В Кремле голубые не только ели, но и пили” (предложите свои варианты в комментариях — будет интересно почитать). Есть ещё “казнить нельзя помиловать”, но эта двусмысленность разрешается запятой.
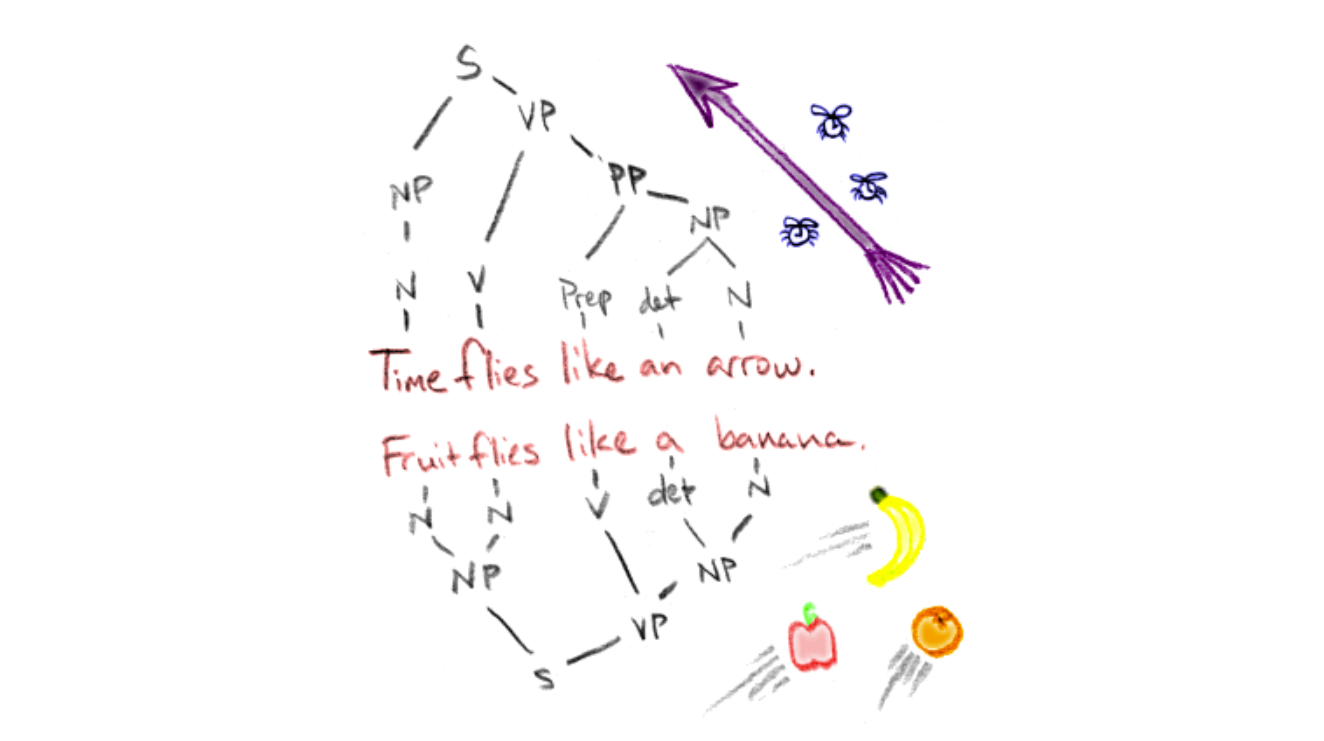
Самый известный пример в английском: “Time flies like an arrow; Fruit flies like a banana”.
Человек скорее всего после некоторых раздумий поймёт это как “Время летит как стрела, мухи любят банан” (хотя мне, например, понадобилось на это несколько секунд). Яндекс переводчик понимает эту фразу так: “Время летит как стрела, фрукты разлетаются как бананы”. Google translator демонстрирует зоологическую эрудированность: “Время летит как стрела; Фруктовые мушки, как банан”, а ChatGPT предлагает “Время летит как стрела; Мухи на фруктах летают как бананы”. В общем, никто не справился.