⚡️ PyWinAssistant — AI-инструмент для управления пользовательским интерфейсом
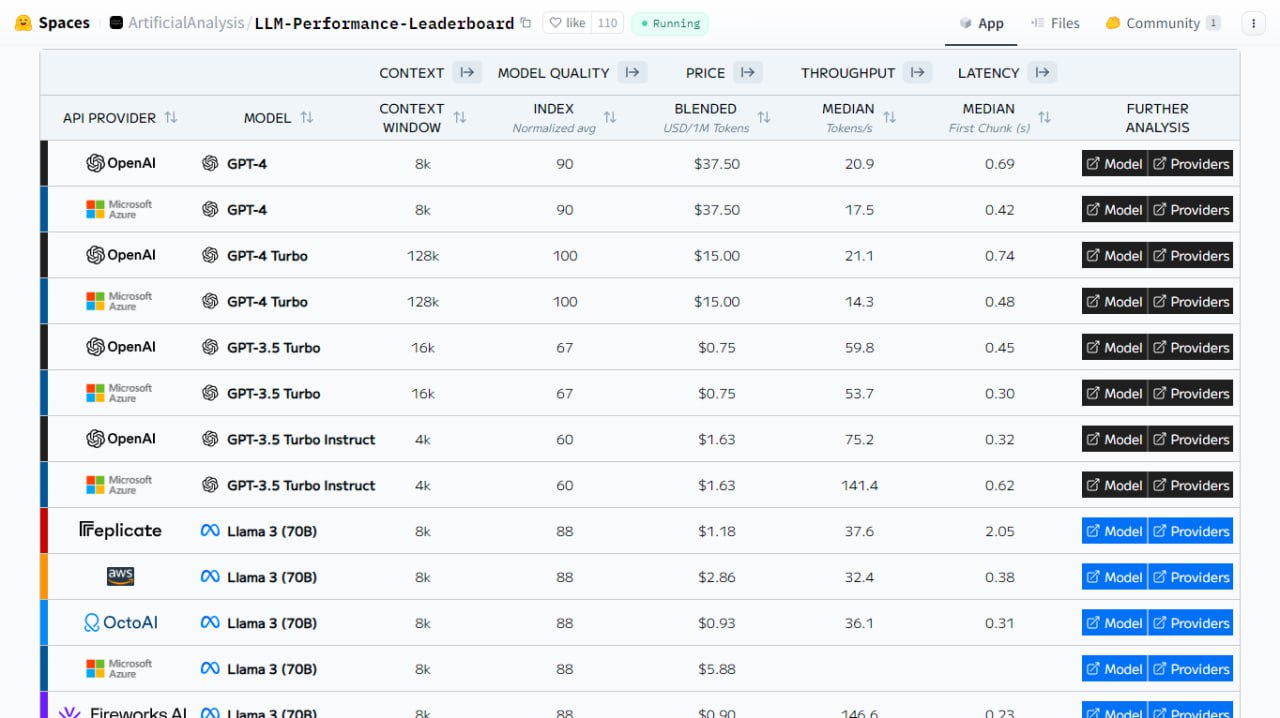
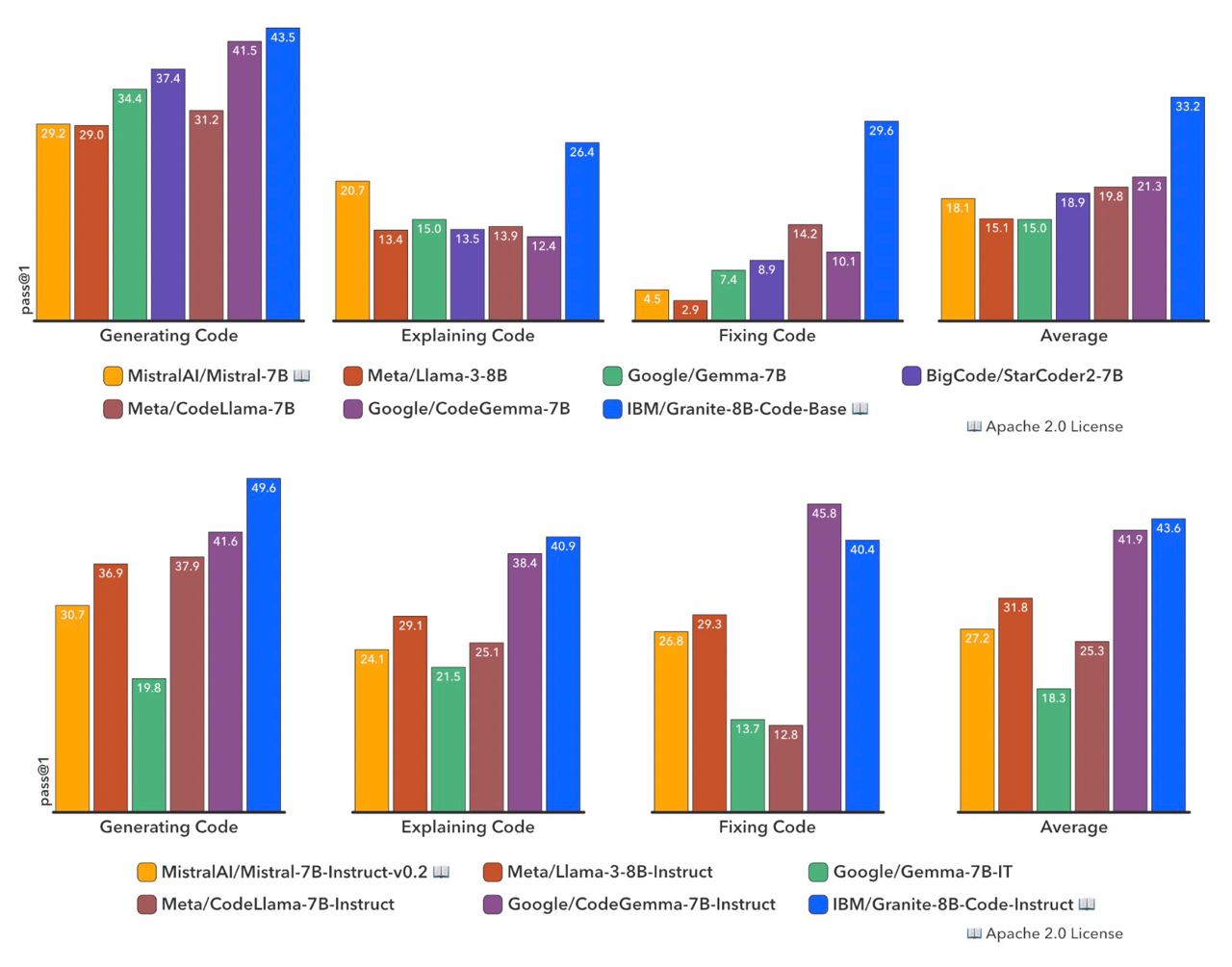
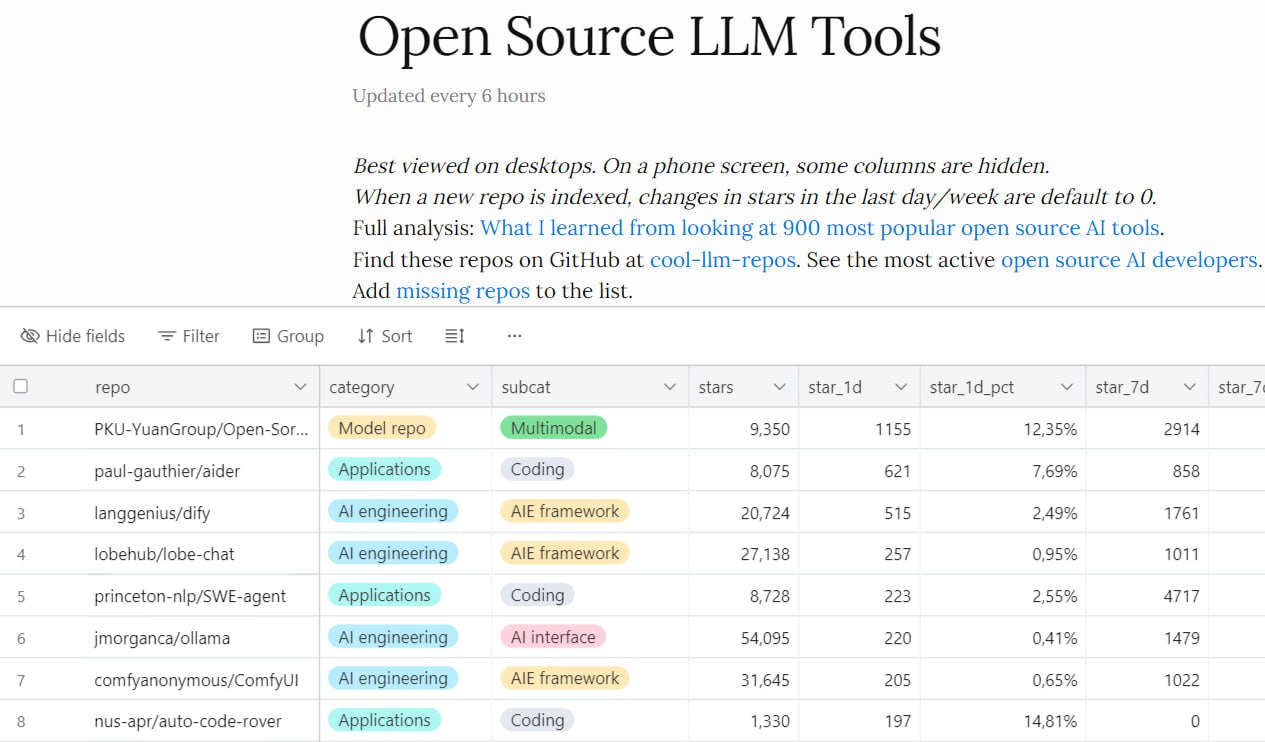
PyWinAssistant — это первый AI-фреймворк для Windows 10/11 с открытым исходным кодом для управления любыми пользовательскими интерфейсами win32api путем использования визуализации мышления (VoT) и пространственных рассуждений в LLM (без OCR / обнаружения объектов / сегментации — такой подход улучшает качество работы PyWinAssistant).
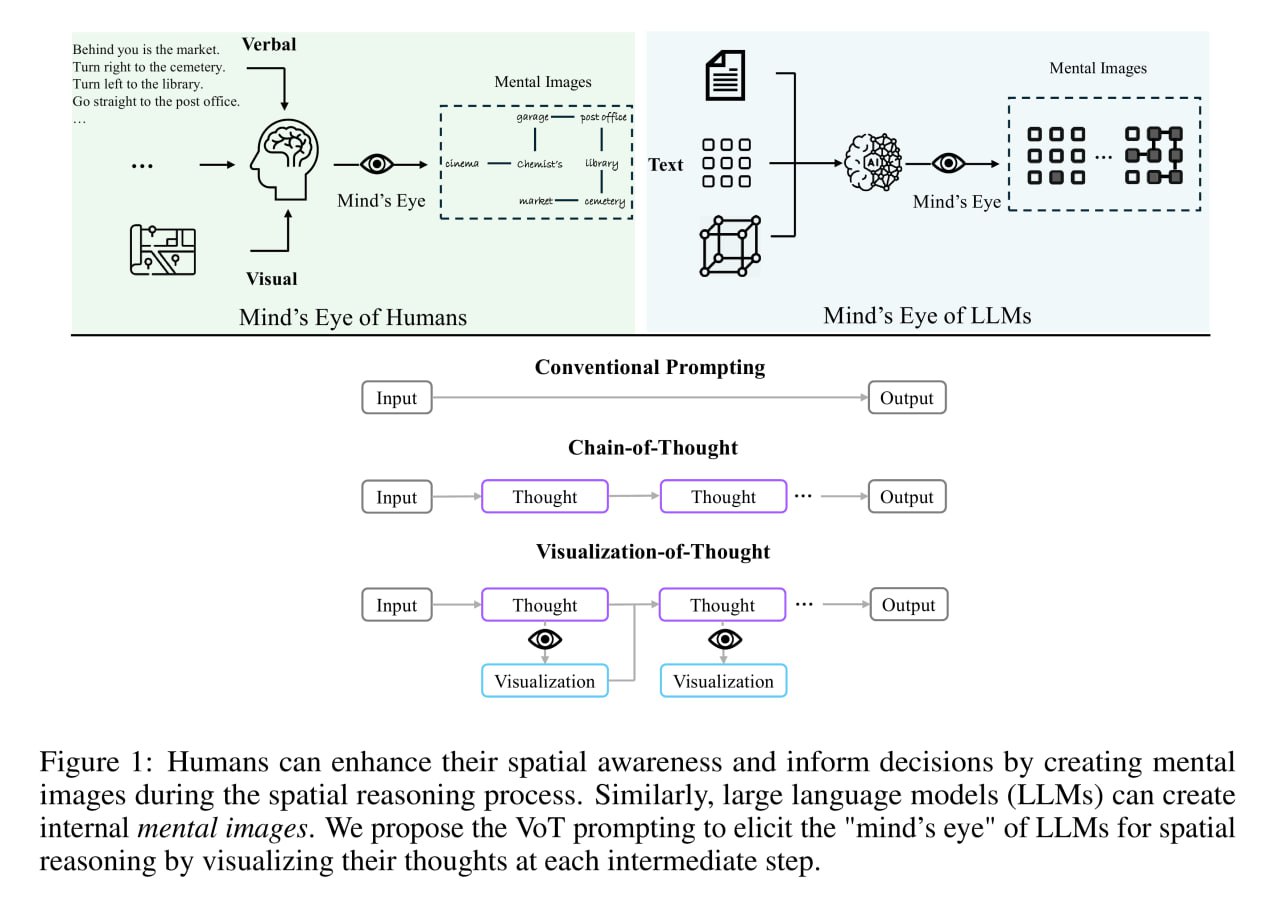
PyWinAssistant имеет встроенные опции чтобы помогать человеку пользоваться компьютером.
Он правильно понимает любые запросы на естественном языке и планирует выполнение правильных действий в ОС с учетом требований безопасности.
🖥 GitHub
🟡 Arxiv (связанное с этим исследование)
Если интересуетесь машинным обучением и ИИ, здесь я публикую разбор свежих LLM и их разбор, статьи и гайды, кладезь полезной информации.
#машинноеобучение #deeplearning