
Исследовательская компания Gartner хорошо известна на рынке аналитики информационных технологий. Я бы даже сказал — является одним из лидеров этого рынка. Ежегодно она выкладывают крайне интересный график, именуемый «Цикл зрелости технологий» (в англ. Hype cycle, или дословно – «цикл шумихи»). На этом графике, в хронологическом порядке, разложены технологии, которые либо уже готовы к применению, либо только-только вступают в стадию исследований.
Вот так выглядит график на 2013 год (выполнен по состоянию на июль 2012 года):

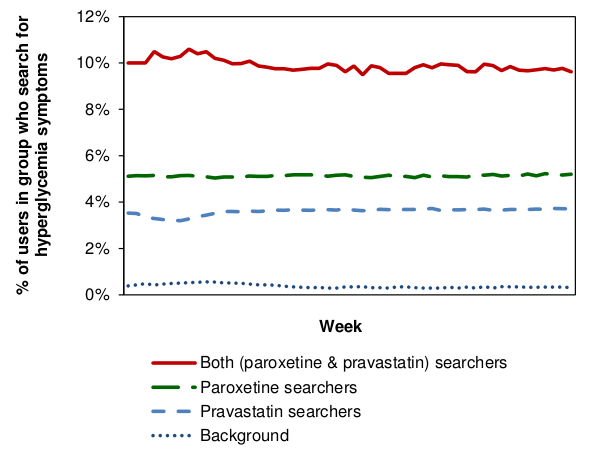
Итак, график делится на пять частей. Первая – «технологический триггер». Т.е. то время, когда технология только-то начинает свое существование (хотя бы в виде идеи). Этап второй – «пик завышенных ожиданий». Т.е. период времени, когда о технологии начинает узнавать общественность. На вершине этого пика о технологии говорят все и на каждом углу, и даже бульварная пресса начинает писать об этом как о почти свершившемся факте. Дальше следует «пропасть разочарования», т.е. то время, когда оказывается, что в реальности технология позволяет делать совсем не то, что от нее хотели. Из этой пропасти выбираются далеко не все. Ну и следом идет «склон просвещения» и «плато продуктивности», по сути – последние этапы перед массовым внедрением.
Вот так выглядит график на 2013 год (выполнен по состоянию на июль 2012 года):
Итак, график делится на пять частей. Первая – «технологический триггер». Т.е. то время, когда технология только-то начинает свое существование (хотя бы в виде идеи). Этап второй – «пик завышенных ожиданий». Т.е. период времени, когда о технологии начинает узнавать общественность. На вершине этого пика о технологии говорят все и на каждом углу, и даже бульварная пресса начинает писать об этом как о почти свершившемся факте. Дальше следует «пропасть разочарования», т.е. то время, когда оказывается, что в реальности технология позволяет делать совсем не то, что от нее хотели. Из этой пропасти выбираются далеко не все. Ну и следом идет «склон просвещения» и «плато продуктивности», по сути – последние этапы перед массовым внедрением.
















 Недавно нам удалось пообщаться с великим Монти — Майклом Видениусом, автором оригинальной версии открытой СУБД MySQL, который в настоящее время работает над ее ответвлением, MariaDB. (Кстати, обе эти базы поддерживаются в
Недавно нам удалось пообщаться с великим Монти — Майклом Видениусом, автором оригинальной версии открытой СУБД MySQL, который в настоящее время работает над ее ответвлением, MariaDB. (Кстати, обе эти базы поддерживаются в 