Какое-то время назад я проводил анкетирование на тему зарплат разработчиков. Пришло время рассказать о полученных результатах.
Всего было заполнено около 1900 анкет разработчиками из более чем 300 городов, преимущественно из России и Украины.
В первую очередь хотелось бы поблагодарить всех добровольцев, которые не пожалели нескольких минут на заполнение анкеты и всех, кто поддержал инициативу на хабре.
Всего было заполнено около 1900 анкет разработчиками из более чем 300 городов, преимущественно из России и Украины.
В первую очередь хотелось бы поблагодарить всех добровольцев, которые не пожалели нескольких минут на заполнение анкеты и всех, кто поддержал инициативу на хабре.


 Продолжаем описание
Продолжаем описание  Этим постом мы продолжаем
Этим постом мы продолжаем  У нас великолепная работа — нам платят за просмотр порнографических роликов. Ну а серьезнее, мы работаем в R&D отделе компании
У нас великолепная работа — нам платят за просмотр порнографических роликов. Ну а серьезнее, мы работаем в R&D отделе компании 



















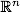 . Координаты вектора описывают отдельные аттрибуты объекта. Например, цвет c, заданный в модели RGB, является вектором в трехмерном пространстве: c=(red, green, blue).
. Координаты вектора описывают отдельные аттрибуты объекта. Например, цвет c, заданный в модели RGB, является вектором в трехмерном пространстве: c=(red, green, blue).