Большие языковые модели (LLM) и созданные на их основе трансформер-модели, такие как GPT-4 как оказалось прекрасно подходят не только для написания текстов, но и для перевода их на другие языки. Тот же нейросетевой переводчик DeepL завоевал свою популярность тем, что выходящие из-под его «пера» тексты не вызывают резкого когнитивного диссонанса у «native» читателей (хотя стоит признать, уровень перевода часто сравним с техподдержкой из одной густонаселенной страны). Авторы DeepL обходят стороной вопрос лежащей в его основе модели, но судя по публикациям, там тоже применяется архитектура Transformer.
В свою очередь автор данных строк уже применял нейросети, а именно Stable Diffusion, для работы с графикой, и обновив в своем компьютере с процессором Intel i5 11 поколения и 16 Гб ОЗУ видеокарту на Nvidia RTX 4060 с 8 гигабайтами памяти, мне захотелось опробовать ее не только на генерации и переносе стилей, но и для других целей. Да, хотелось бы 4090, но для повседневных задач мне ее мощности с избытком и только если попробовать арендовать ее или ту же A5000 на VPS-хостинге.
Ищем пациента для имплантации.
По рабочим вопросам, я применяю DeepL для перевода технической документации, так как необходимое качество «подстрочника» он обеспечивает и ускоряет работу над однотипными текстами, которые после остается только вычитать и поправить явные ляпы в оборотах и терминологии. Поэтому захотелось посмотреть, а что можно применить взамен, особенно учитывая намеки авторов переводчика скоро прикрыть «халяву» с бесплатным AI Writer.
Для начала я сравнил качество перевода с русского на английский в Copilot (в нем используется та же модель, что и в ChatGPT-4), в новом YandexGPT и в GigaChat от Сбера. В результате получил примерно одно и тоже, но не дотягивающего до DeepL. Все-таки LLM модели грешат использованием «литературно-устаревших» терминов и оборотов, которые в реальной жизни малоприменимы. Также посмотрел на переводы от Google, MS и свободных решений на основе Opus (тот же Libretranslate, который зато работает быстро). По моему личному мнению, для руководств они дают еще худший вариант.
Все это также требовалось прикрутить к рабочей среде, в которой я издеваюсь над статьями и, казалось бы, VS Code должен иметь большую библиотеку решений для этого. Не буду томить – да, к нему можно прикрутить известные переводчики, но для этого надо получить API ключи (а для DeepL еще и платно и с ограничением на число символов), и перевод там выполняется в режиме «я за тебя сделаю Ctrl+C, вставлю в окно перевода, потом скопирую перевод назад». Это можно сделать и руками и даже быстрее, чем через API. Про улетающее в неизвестность форматирование разметки Markdown уже молчу.
GPT и LLM модели также прикручиваются к VS Code, но в основном плагины предназначены для создания Copilot, чтобы было легче писать именно код. А мне нужен был именно перевод и с возможностью в дальнейшем расширить его не только на английский язык, но и, например для пар «английский -турецкий» или даже «английский-китайский»
Еще одна загвоздка для меня лично – корпоративный VPN, через который идет доступ к gitlab проектов. AnyConnect в Windows не уживается одновременно с тем же Hiddify Next, а для доступа к API многих коммерческих GPT-моделей (и веб-интерфейсам) нужна подмена IP на не российский. Идеальным решением было бы развертывание локального сервера, на котором бы крутилась языковая модель и к которой бы уже обращался плагин в Visual Studio Code. И чтобы это все еще и могла вытянуть моя видеокарта и поместилось в 16 Гб ОЗУ оперативки.
Собираем франкенштейна
Сломав голову теорией и перепробовав разные решения, нашел достаточно рабочий вариант. Им оказалась связка LM Studio и плагина Continue. Итак, разберем процесс сборки своей «студии машинного перевода» по шагам. Я буду делать это под Windows (все-таки у меня Visual Studio Code), но под Linux должно работать близко к данному мануалу:
1. Качаем и устанавливаем на компьютер LM Studio с официального сайта: https://lmstudio.ai/. Проект в стадии развития, закрытый и скорее всего будет платный для коммерческого использования, так как сейчас по лицензии он free только для ознакомления и некоммерции. Это не беда, подобные «движки» моделей есть и opensource и их можно прикрутить к плагину, а LM Studio также не требует от вас установки Python, PyTorch и библиотек CUDA для питона.
2. Запускаем LM Studio и, забив в строку поиска Starling-LM-7B-beta-GGUF, качаем модель Starling-LM-7B-beta-Q6_K.gguf. Модель объемом почти в 6 Гб c 6-битной К-квантизацей. Да, квантизация снижает точность модели, но позволяет запихать ее даже в 8 Гб памяти видеокарты. Из опробованных ранее моделей эта понравилась мне больше всего. Хотя я не пробовал еще модели на 7–7.5 Гб, которые в теории должны работать.
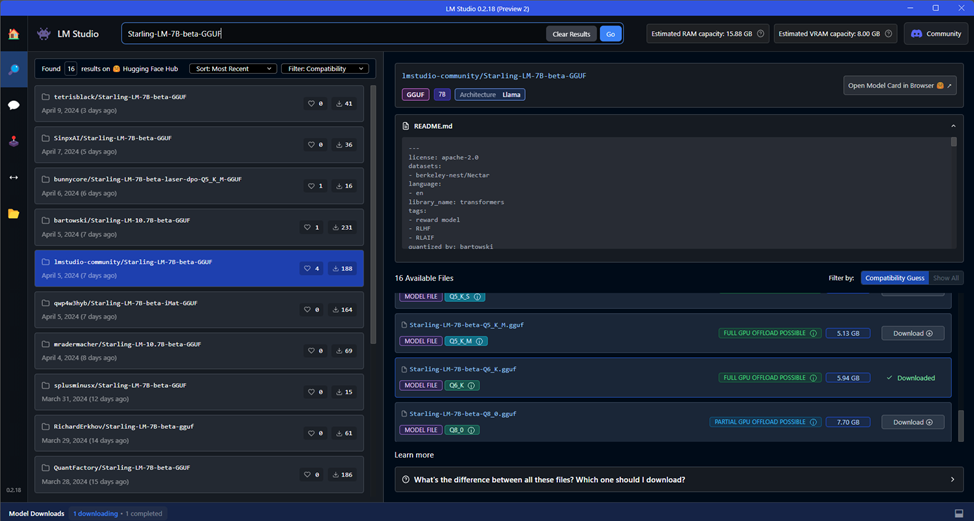
Скачав модель (это можно посмотреть, нажав на Model Downloads в нижнем левом углу, вы можете сразу же посмотреть ее в действии, перейдя во вкладку AI Chat и выбрав модель из выпадающего списка сверху.
Почему именно эта модель? Я попробовал другие доступные модели в формате GGUF, и именно модель, основанная на openchat 3.5 (а он в свою очередь на модели Mistral) показала хорошие результаты по скорости и качеству. Я также попробовал улучшенную модель с 10.7 биллионами параметров (хотя сама LM Studio пишет, что модель 34B), но она работает гораздо медленней и мой компьютер не хило так притормаживает при работе. Хотя перевод дает качественней.

3. Запускаем сервер в LM Studio. Для этого переходим во вкладку Local Server (стрелочка туда-сюда) и выбираем из верхнего выпадающего меню модель, ждем ее загрузки и нажимаем на Start Server. Все параметры можно оставить дефолтными.

4. Переходим в VS Code, находим и ставим плагин Continue.

5. Переходим во вкладку с буквами C и D, потом нажимаем на плюсик рядом с выпадающим списком в левом нижнем углу и находим в списке для подключения LM Stuido.

6. Нажав на этот пункт, выбираем далее Autodetect

Должен открыться файл конфигурации config.json, в котором будет прописано подключение LM Studio. После этого появиться надпись, что модель подключена, а в левом нижнем углу появится название этой модели и зеленый «огонек», что все загружено.
На этом этапе вы уже получите AI ассистента для написания программ (только модель лучше скачать специализированную), но нам надо теперь научиться переводить текст и желательно сохранить побольше форматирования.
Учимся переводить
Далее можно, зная JavaScript, переписать под себя код плагина, или использовать возможности вызова контекста промта через коротки слэш-команды. Сделаем второй вариант.
Для этого (если уже закрыли), открываем конфигурационный файл config.json нажав на шестеренку во вкладке плагина.

В открывшемся файле дописываем в разделе customCommands после секции test такой код
{
"name": "trEN",
"prompt": "Translate the selected code from Russian to US English. Your reply should contain ONLY the translated text, nothing else. Please use exactly the same formatting as the original text.",
"description": "Перевод текста US English"
}Не забудьте поставить после закрывающей фигурной скобки секции test запятую.
Что он означает:
name – это слэш-команда контекста, который можно вызывать в окне плагина нажав на /.
prompt – команда для нейросети перевести наш текст с русского на американский английский с выводом только текста перевода (забегая вперед скажу, что нейросеть из-за одного параметра, который увы «зашит» в LM Studio не всегда слушается) и сохранения форматирования.
description – описание для слэш-команды, чтобы не забыть про что она.
Сохраняемся и проверяем результат. Для этого открываем нужный нам файл, выделяем кусок текста для перевода и нажав на правую кнопку мыши вызываем пункт меню Continue – Add Highlighted Code to Context (или нажимаем Ctrl + Shift + L).

В окне плагина должен появиться выделенный текст и курсор будет мигать в зоне контекста запроса. Тут можно или написать словами, что мы хотим сделать (даже на русском) или нажать на / и выбрать нашу команду /trEn.

Потом нажать на Enter и ждать результата перевода. Скорость перевода можно регулировать в LM Studio изменяя значение параметра GPU Offload в разделе Hardware Acceleration, но стоит помнить, что большое значение приводит к накапливанию и появлению ошибок. Оптимально подобрать его под себя, у меня оно равно 15.
Перевод иногда сразу же идет в разметке Markdown, но иногда нет, поэтому я добавил вторую команду /format в conf.json. Помните о запятых, которыми отделены секции в файле, кроме последней!
{
"name": "format",
"prompt": "Format code as original markdown",
"description": "Формат текста"
}Эту слэш-команду вызываю, добавив после /format двухбуквенный код языка перевода (например EN). Отформатированный текст можно вставить на место в документ, нажав на средний значок Insert of cursor в окне с текстом.

Если модель начала бредить или что-то подглючивает, то для начала перезапустите сессию, нажав на надпись New Session в левом нижнем углу.

Если не помогает – перейдите в LM Studio, остановите и снова запустите сервер.
Таким же образом можно настроить перевод на другие языки. В моем случае я проверил перевод на три языка: турецкий, китайский и голландский. Не могу оценивать качество, но переводит. Также я добавил команды для лингвистической проверки текстов, но универсальные модели синтаксис и орфографию проверяют, мягко говоря, странно и тут лучше пользоваться российскими моделями от Яндекс или Сбера (я использую нейроредактор от Яндекса в Яндекс Браузере).
LM Studio должен работать и на CPU с поддержкой AVX-2 и на «маках» с процессорами M1-M3, а для владельцев AMD видеокарт там есть специальная версия с поддержкой ROCm.
В принципе я доволен скоростью работы и для перевода текстов в рабочем ритме ее хватает, но для масс-перевода документации я все-таки напишу скрипт для перевода файлов и арендую для размещения нейросети VPS-сервер с RTX 4090 для скорости и качества.
Что дальше? Я хочу попробовать разницу в работе моделей с большим числом параметров и на более мощном оборудовании (например, на Nvidia H100 можно запускать модели 70B), другие способы их подключения через ту же ollama, другие модели (тот же Google выпустил Gemini 1.1) и даже попробовать поработать с эмбендингами на основе наших готовых текстов и документов. Если вам интересна эта тема, поделитесь своими успехами, замечаниями и дополнениями в комментариях.
AI FREE - данный текст написан человеком без использования нейросетей.

Телеграм канал с новостями об AI, ЦОД, серверах, облаках и других событиях из жизни хостинга 💻
