Всем привет! Я реализовал, похоже, собственный алгоритм поиска кратчайшего пути с отрицательными ребрами графа.
Почему собственный? Я искал подобное решение, но не нашел, возможно, оно уже было реализовано, просто плохо поискал. Жду Нобелевскую премию =)
Додумался я до него путем модификации классического Дейкстры. Прошу адекватно отнестись к содержимому, ибо это моя первая статья, и, возможно, я ничего не придумывал и, вообще, этот алгоритм не работает вовсе (но по многочисленным тестам он работает правильно).
Повторюсь, алгоритм работает с отрицательными ребрами графа (но не с циклическими отрицательными). Чем этот алгоритм отличается от известного Беллмана-Форда?
Эвристической сложностью! У известного алгоритма сложность составляет O(En), где n - количество узлов, Е - количество ребер. У "моего" алгоритма такая же ассимптотическая сложность. Но по моим расчетам худшая сложность в большинстве случаев не достигается. А у Беллмана-Форда худших случаев намного больше (об этом далее). Более того, в среднем алгоритм не превышает оригинальной сложности алгоритма Дейкстры, а именно O(n2+E). Об этом тоже напишу далее. Реализация на языке Python:
P.S.
В статье исправлены многие моменты, спасибо сообществу за тест-кейсы и подсказки. Некоторые комментарии не будут актуальными (в том числе саркастически-оскорбительные), т.к. я считаю, что доказал работоспособность алгоритма.
Реализация

Итак, у нас есть граф с отрицательным ребром между 2-м и 5-м узлом. Наша задача - найти кратчайший путь от источника (1-го узла) до 9-го узла (либо до любого другого достижимого).
Граф будет храниться в виде хэш таблицы, где:
graph = {
нода_1_(источник): {сосед_1: вес до него, сосед_2: вес до него, ...},
нода_2: {сосед_1: вес до него, сосед_2: вес до него, ...},
...
}
graph = {
1: {2: 10, 3: 6, 4: 8},
2: {7: 11, 4: 5, 5: -4},
3: {5: 3},
4: {7: 12, 3: 2, 5: 5, 6: 7},
5: {6: 9, 9: 12},
6: {8: 8, 9: 10},
7: {6: 4, 8: 6, 9: 16},
8: {9: 15},
9: {}
}Важно! Нужно писать узлы графа в порядке их отдаленности от источника. Т.е. сперва описываем первых соседей источника. После того, как описали их, приступаем к следующим соседям соседей. Т.е. описываем поуровнево, будто это не взвешенный граф, а обыкновенное дерево, где реализовываем поиск в ширину. В Python словари являются упорядоченными (начиная с версии 3.6), поэтому нам не стоит прибегать к другим структурам данных, типа Ordered dict из модуля collections.
Можно описать граф матрицей смежностей, но мне так проще.
P.S. Тот, кто задается подобным вопросом:
Определение графа знаете? Набор вершин и дуг, в котором дуги являются парами связных вершин, плюсом веса для дуг в нашем случаи. Никакого порядка там в принципе не предусмотрено.
Заранее отвечаю.
Хорошо, буду от вашей структуры отталкиваться. У нас какая задача? Найти кратчайший путь из точки А в точку В. Находим в вашем представлении графа точку А и смотрим на его соседей. Потом находим этих соседей и смотрим их соседей и т.д. Вот это "находим" в вашей беспорядочной структуре будет за N выполняться N раз. Это будет в том случае, если ноды у вас просто беспорядочно расположены в массиве (если вы используете эту структуру данных для хранения). Обычно в программе номер ноды совпадает с номером ячейки в массиве, что позволяет получить к этой ноде доступ за константу. В алгоритме Дейкстры (не я придумал его) как раз таки задача решается именно таким представлением графа, где номер ноды (или буква в лексиграфическом порядке) совпадает с номером ячейки в массиве. То, как вы пытаетесь представить граф - это по сути выстрел себе в ногу. Если отталкиваться от реальной жизни, нужно еще реализовать построение такой структуры графа. Условно ты находишься на перекрестке 1, мне надо в перекресток 10. А дай ка гляну, какие там дороги исходят из перекрестка 7 и запишу. Хотя можно было на второе место записать дороги перекрестка 2. В общем, замечание ваше понятно, но это всё общепринятая условность представления данных графа, я это не придумывал.
Поиск в ширину же выполнится за линейное время, поэтому он никак не увеличивает сложность алгоритма.
Допустим, если дана задача, где на вход подается граф вида: input_graph = [[узел_2, узел_5, вес до узла_5], [узел_7, узел_1, вес до узла_1] ...], число n - количество узлов, k - узел-источник, с которого нужно найти кратчайший путь до всех достижимых вершин (обычно в задачах гарантируется, что все вершины достижимы, но если вдруг этой гарантии нет, то это нужно будет дополнительно обрабатывать этот момент, эту обработку я так же покажу). Код построения моей структуры будет такой:
from collections import deque
input_graph = [[1, 2, 10], [2, 1, 10], [3, 2, 1]]
n = int(input()) # 3
k = int(input()) # 1
arr = [[] for _ in range(n + 1)]
graph = {}
for item in input_graph:
arr[item[0]].append((item[1], item[2]))
queue = deque()
graph[k] = {}
for i in arr[k]:
neighbor = i[0]
graph[k][neighbor] = i[1]
queue.append(neighbor)
while queue:
current = queue.popleft()
if current not in graph:
graph[current] = {}
for i in arr[current]:
neighbor = i[0]
if neighbor not in graph:
graph[i[0]] = {}
queue.append(neighbor)
graph[current][neighbor] = i[1]
# -> graph = {1: {2: 10}, 2: {1: 10}}
# 3-я вершина не будет в этой структуре, т.к. она недостижима с 1-ой ноды!
# Если бы k=3, тогда:
# graph = {3: {2: 1}, 2: {1: 10}, 1: {2: 10}}}С этим разобрались, идем дальше.
Так же нам понадобится еще 2 хэш таблицы.
Минимальные веса от источника до этой ноды в виде:
costs = {
нода_1_(источник): 0,
нода_2: infinity,
нода_3: infinity,
...
}
Заполнять и обновлять мы ее будем по мере прохождения по "детям" узлов.
costs = {} # Минимальный вес для перехода к этой ноде (кратчайшие длины пути до ноды от начального узла)Таблица родителей нод, от которых проходит кратчайший путь до этой ноды:
parents = {} # {Нода: его родитель}Ее так же будем заполнять и обновлять по мере прохождения по детям узлов.
Как и в алгоритме Дейкстры, будем отмечать еще неизвестные до узлов расстояния бесконечностью. Инициализируем эту переменную:
infinity = float('inf') # Бесконечность (когда минимальный вес до ноды еще неизвестен)Далее создаем пустое множество. Там будут храниться обработанные узлы (что значит "обработанные", поясню далее, а пока просто создаем множество)
processed = set() # Множество обработанных нодВведем новую структуру данных - список очередности обработки узлов графа.
lst = deque([key for key in graph.keys()]) # Формируем очередность прохождения узлов графаПриступим к самому алгоритму!
Начинаем с источника (первого узла). Смотрим на веса всех его соседей в таблице costs. Путь до них бесконечный, а любое число уже меньше бесконечности, поэтому обновляем веса. Так же вносим родителей всех узлов, т.к. мы обнаружили путь до ноды короче. Когда посмотрели всех соседей, вносим наш рассматриваемый узел в множество обработанных узлов processed (этот узел мы не будем обрабатывать в дальнейшем).
Здесь важный момент и отличие от алгоритма Дейкстры. Мы будем смотреть не минимальный по весу необработанный узел, а смотреть вообще ВСЕХ соседей поочередно. Т.е. у нас есть соседи после первого этапа алгоритма.
Мы поочередно так же будем искать уже их соседей и обновлять минимальные веса. Если же достижимый вес окажется меньше, чем внесенный в таблицу, то мы его заменяем. Так же заменяем его родителя в таблице parents.
Когда посмотрели всех соседей, вносим узел в множество обработанных. Т.е. множество обработанных - это те узлы, у которых мы рассмотрели всех его соседей!И так повторяем поуровнево (не приступаем к соседям соседей, пока не обработаем первых соседей), пока не будут обработаны все узлы.
Список очередности будет служить нашей итерабельной последовательностью первого цикла. Зачем? Если вдруг у ноды соседом будет уже обработанная нода, то мы эту ноду снова будем обрабатывать, т.к. веса детей могут стать меньше.
Код:
from collections import deque
graph = {
1: {2: 10, 3: 6, 4: 8},
2: {7: 11, 4: 5, 5: -4},
3: {5: 3},
4: {7: 12, 3: 2, 5: 5, 6: 7},
5: {6: 9, 9: 12},
6: {8: 8, 9: 10},
7: {6: 4, 8: 6, 9: 16},
8: {9: 15},
9: {}
}
lst = deque([key for key in graph.keys()]) # Формируем очередность прохождения узлов графа
parents = {} # {Нода: его родитель}
costs = {} # Минимальный вес для перехода к этой ноде (кратчайшие длины пути до ноды от начального узла)
infinity = float('inf') # Бесконечность (когда минимальный вес до ноды еще неизвестен)
processed = set() # Множество обработанных нод
while lst:
node = lst.popleft()
if node not in processed: # Если нода уже обработана не будем ее заново смотреть (иначе м.б. беск. цикл)
for child, cost in graph[node].items(): # Проходимся по всем детям
new_cost = cost + costs.get(node,
0) # Путь до ребенка = путь родителя + вес до ребенка (если родителя нет, то путь до него = 0)
min_cost = costs.get(child,
infinity) # Смотрим на минимальный путь до ребенка (если его до этого не было, то он беск.)
if new_cost < min_cost: # Если новый путь будет меньше минимального пути до этого,
costs[child] = new_cost # то заменяем минимальный путь на вычисленный
parents[child] = node # Так же заменяем родителя, от которого достигается мин путь
if child in processed: # Если ребенок был в числе обработанных
lst.appendleft(child) # Вновь добавляем эту ноду в список для того, чтобы обработать его заново
processed.remove(child) # Удаляем из обработанных
processed.add(node) # Когда все дети (ребра графа) обработаны, вносим ноду в множество обработанных
print(f'Минимальные стоимости от источника до ноды: {costs}')
print(f'Родители нод, от которых исходит кратчайший путь до этой ноды: {parents}')
# -> Минимальные стоимости от источника до ноды: {2: 10, 3: 6, 4: 8, 7: 20, 5: 6, 6: 15, 9: 18, 8: 23}
# -> Родители нод, от которых исходит кратчайший путь до этой ноды: {2: 1, 3: 1, 4: 1, 7: 4, 5: 2, 6: 4, 9: 5, 8: 6}Мы получили кратчайшие расстояния от источника до каждого достижимого узла в графе, а так же родителей этих узлов. Как же нам построить цепочку интересующего нас пути от источника до 9-ой ноды (либо до любой другой достижимой)? Ответ в коде ниже:
def get_shortest_path(start, end):
'''
Проходится по родителям, начиная с конечного пути,
т.е. ищет родителя конечного пути, потом родителя родителя и т.д. пока не дойдет до начала пути.
Тем самым мы строим обратную цепочку нод, которую мы инвертируем в конце, чтобы получить
истинный кратчайший путь
'''
parent = parents[end]
result = [end]
while parent != start:
result.append(parent)
parent = parents[parent]
result.append(start)
result.reverse()
result = map(str, result) # В случае если имена нод будут числами, а не строками (для дальнейшего join)
shortest_distance = costs[end]
print(f'Кратчайший путь от {start} до {end}: {shortest_distance}')
return result
shortest_path = get_shortest_path(start=1, end=9)
print('-->'.join(shortest_path))
# -> Кратчайший путь от 1 до 9: 18
# -> 1-->2-->5-->9Итак, мы нашли кратчайший путь до 9 узла, и обратите внимание, он проходит через ребро с отрицательным весом! Т.е. нас теперь не пугает наличие такого ребра, в отличие от оригинальной Дейкстры.
Еще деталь такая. При реализации классической Дейкстры, в случае, когда поиск МИНИМАЛЬНОГО по весу узла совпадет с нашим конечным целевым узлом,
то мы можем прервать дальнейшую обработку, т.к. мы уже нашли кратчайший путь до интересующего узла. В "моем" же алгоритме мы все равно будем обрабатывать все узлы.
Сложность
Что касается сложности данного алгоритма, то в наихудшем случае она будет такая же, как у Беллмана-Форда - O(N*E). Но я так и не нашел наихудший случай. Во всех случаях, которые я тестировал, он работал быстрее Беллмана-Форда. Давайте рассуждать.
Смоделируем ситуацию "в лоб". Посчитаем количество операций на наихудшем графе, который мне прислали, где алгоритм чувствуте себя несколько хуже, чем на других примерах. Пример графа (извиняюсь за ручной рисунок)
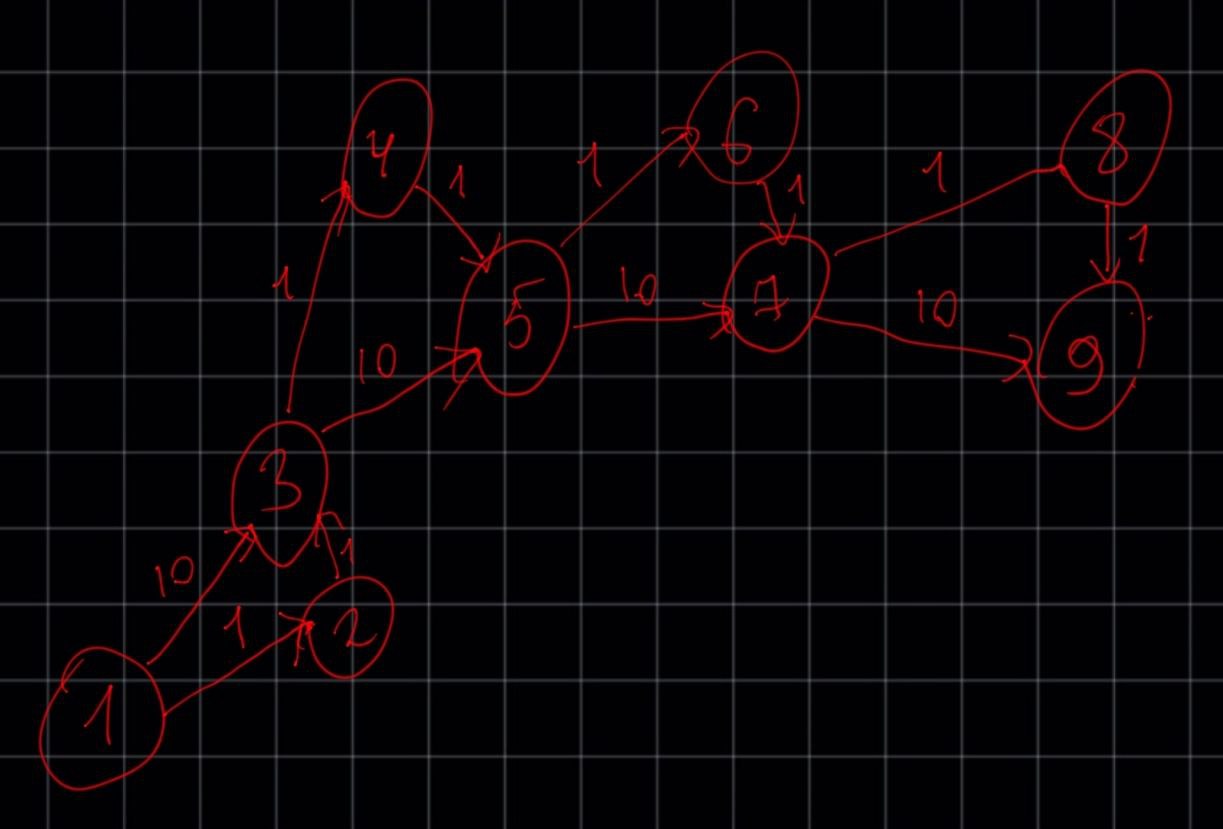
graph = {
1: {3:10, 2:1},
3: {5:10, 4:1 },
2: {3:1},
5: {7:10, 6:1 },
4: {5:1},
7: {9:10, 8:1},
6: {7:1},
9: {},
8: {9:1},
}
cycle_count = 0
processed = set() # Множество обработанных нод
while lst:
node = lst.popleft()
if node not in processed: # Если нода уже обработана не будем ее заново смотреть (иначе м.б. беск. цикл)
for child, cost in graph[node].items(): # Проходимся по всем детям
cycle_count += 1
new_cost = cost + costs.get(node,
0) # Путь до ребенка = путь родителя + вес до ребенка (если родителя нет, то путь до него = 0)
min_cost = costs.get(child,
infinity) # Смотрим на минимальный путь до ребенка (если его до этого не было, то он беск.)
if new_cost < min_cost: # Если новый путь будет меньше минимального пути до этого,
costs[child] = new_cost # то заменяем минимальный путь на вычисленный
parents[child] = node # Так же заменяем родителя, от которого достигается мин путь
if child in processed: # UPDATE: если ребенок был в числе обработанных
lst.appendleft(child) # Вновь добавляем эту ноду в список для того, чтобы обработать его заново
processed.remove(child) # Удаляем из обработанных
processed.add(node) # Когда все дети (ребра графа) обработаны, вносим ноду в множество обработанных
print(f'Количество операций: {cycle_count}')
# -> Количество операций: 19
# По Беллману-Форду было бы: 9*12=108 судя по формуле (условно)По Беллману-Форду количество операций, судя по формуле, превышает более чем в 5 раз!
Вы можете сказать: "да это просто граф такой попался". Что-ж рассмотрим граф, который является 100% наихудшим случаем для Беллмана-Форда, судя по информации из открытых источников.
Представим такого вида линейный граф: 1-->2-->3-->4-->5. Где каждое ребро имеет вес 1. По Беллману-Форду кол-во операций свелось бы как раз к его формуле (наихудшему случаю), а именно 5*4=20. В моем алгоритме:
graph = {
1: {2:1},
2: {3:1},
3: {4:1},
4: {5:1},
5: {},
}
# -> Количество операций: 4Т.е. по сути алгоритм выполнился линейно за O(E).
Если я что-то неправильно сделал, может быть, глупость совершил, что в "лоб" посчитал количество операций, то с радостью выслушаю, в чем мой "косяк". Но вроде как взял наихудшие случаи.
Что касается алгоритма классического Дейкстры, то его сложность не сильно лучше. НО! У него есть реализация с двоичной и фибоначчиевой куч. Вот реализация с помощью таких структур дает сильный буст этого алгоритма. Поэтому, если в задаче нет отрицательных ребер, то следует использовать именно такие алгоритмы, нежели мой. Вы в этом убедитесь в следующем разделе.

Стресс тесты
Итак, после реализации алгоритма мне прислали интересную задачу (отдельное спасибо за нее) с очень и очень каверзными тестами.

Обратите внимание! В этой задаче будут присутствовать узлы, у которых несколько ребер с разными весами направлены на один и тот же узел. Выглядит это вот так:

Это не простой граф. Называется он - мультиграф. С таким графом не справится мой дефолтный алгоритм, поэтому придется обрабатывать такие случаи, что приведет к дополнительным ресурсным расходам. Но сразу скажу, что эти расходы будут "дешевле", чем обработка этих ребер у уже известных алгоритмов. Проблема в том, что если обратить внимание на входные данные, то можно слегка удивиться:
Количество узлов - 100к
Количество ребер - 200к
Максимальные веса ребер - 1 млрд
Очень даже не дурно для такой задачи. Что ж, я ее решил своим алгоритмом! Давайте обсудим по порядку. Результаты можете сами проверить, там сам код, время выполнения и правильность ответа. Я сравнивал мой алгоритм с алгоритмом Дейкстры, реализованном на двоичной куче, классическим Фордом-Беллманом и с SPFA. Запускал на процессоре Ryzen 7 5800X. С временем там сильно интересно! Ссылка на результаты с решениями. Ссылка на саму задачу. Обратите внимание, я взял тесты, где максимальное количество данных. Простые тесты я не включал в расчет, они и так проходят. P.S. не пытайтесь пихнуть мою реализацию алгоритмов в проверочную систему на питоне. Код проверку не пройдет, т.к. упрется в ограничение в 1 сек. Даже самый быстрый из реализованных алгоритмов не уложится ко времени во всех тестах (я пробовал). Возможно, реализация на С++ позволит это сделать, но я не знаком с ним. Возможно, сможете оптимизировать код (реализованный на куче) так, что он сможет пройти проверку. Теперь обсудим результаты.
Если кратко сделать выводы, то мы увидим, что задача, действительно, очень каверзная. В худшем случае обработка будет на 100 000 узлах и 200 000 ребрах! Если перевести все это в количество операций (причем не самых дешевых!), то имеем:
Классический Форд-Беллман (E*n) займет 2*10^5 * 10^5 = 20 млрд операций. SPFA то же самое.
Дейкстра с кучей (Elogn) займет 2*10^5 * 17 = 3.4 млн
Мой алгоритм (E*n) займет 2*10^5 * 10^5 = 20 млрд операций.
Видим, что для этой задачи мой алгоритм и Форд-Беллман не подходит. И даже, в некоторых тестах Дейкстра с кучей тоже не зашла! Плюс там дополнительное время уходит на обработку мультиграфа. Тесты все алгоритмы проходят долго, а иногда очень долго (мультиграф я обрабатывал одинаковым образом для чистоты эксперимента). Но если заметить, мой алгоритм опередил всех своих конкурентов (если, конечно, реализациях их правильная, брал код с интернета, вроде верный)! Так что, эвристическая сложность, считаю, очень и очень хорошей, не смотря на одинаковую сложность. Вот это задача так задача ;)
Самое главное, она решена. Время среднее схоже даже с Дейкстрой с кучей! Форд-Беллман тем более со своей модификацией с очередью (SPFA) сильно отстал от моей реализации. Я был приятно удивлен!
Что ж, я решил еще одну задачу так же 3-мя способами на литкоде. Результаты ниже:
Мой алгоритм:
Hidden text
from collections import deque
class Solution:
def networkDelayTime(self, times, n, k):
arr = [[] for _ in range(n + 1)]
graph = {}
for item in times:
arr[item[0]].append((item[1], item[2]))
queue = deque()
graph[k] = {}
for i in arr[k]:
neighbor = i[0]
graph[k][neighbor] = i[1]
queue.append(neighbor)
while queue:
current = queue.popleft()
if current not in graph:
graph[current] = {}
for i in arr[current]:
neighbor = i[0]
if neighbor not in graph:
graph[i[0]] = {}
queue.append(neighbor)
graph[current][neighbor] = i[1]
lst = deque([key for key in graph.keys()])
parents = {}
costs = {}
infinity = float('inf')
processed = set()
while lst:
node = lst.popleft()
if node not in processed:
for child, cost in graph[node].items():
new_cost = cost + costs.get(node,
0)
min_cost = costs.get(child,
infinity)
if new_cost < min_cost:
costs[child] = new_cost
parents[child] = node
if child in processed:
lst.appendleft(child)
processed.remove(child)
processed.add(node)
max_distance = 0
for i in range(1, n + 1):
if k == i:
continue
distance = costs.get(i, 'No')
if distance == 'No':
return -1
if distance > max_distance:
max_distance = distance
else:
return max_distance
Классический Дейкстра:
Hidden text
from collections import deque
class Solution:
def networkDelayTime(self, times: List[List[int]], n: int, k: int) -> int:
arr = [[] for _ in range(n + 1)]
graph = {}
for item in times:
arr[item[0]].append((item[1], item[2]))
queue = deque()
graph[k] = {}
for i in arr[k]:
neighbor = i[0]
graph[k][neighbor] = i[1]
queue.append(neighbor)
while queue:
current = queue.popleft()
if current not in graph:
graph[current] = {}
for i in arr[current]:
neighbor = i[0]
if neighbor not in graph:
graph[i[0]] = {}
queue.append(neighbor)
graph[current][neighbor] = i[1]
infinity = float("inf")
costs = {}
parents = {}
processed = set()
for v in graph[k]:
costs[v] = graph[k][v]
parents[v] = k
def find_lowest_cost_node(costs):
lowest_cost = infinity
lowest_cost_node = None
for node in costs:
cost = costs[node]
if cost < lowest_cost and node not in processed:
lowest_cost = cost
lowest_cost_node = node
return lowest_cost_node
node = find_lowest_cost_node(costs)
while node is not None:
cost = costs.get(node, infinity)
neighbors = graph[node]
for q in neighbors.keys():
new_cost = cost + neighbors[q]
old_cost = costs.get(q, infinity)
if old_cost > new_cost:
costs[q] = new_cost
parents[q] = node
processed.add(node)
node = find_lowest_cost_node(costs)
max_val = 0
for i in range(1, n + 1):
if i == k:
continue
value = costs.get(i, 'No')
if value == 'No':
return -1
if value > max_val:
max_val = value
return max_val
Дейкстра с кучей:
Hidden text
import heapq,sys
from collections import defaultdict
class Solution:
def networkDelayTime(self, times: List[List[int]], n: int, k: int) -> int:
adj = defaultdict(list)
for t in times:
adj[t[0]].append((t[2],t[1]))
q=[]
heapq.heapify(q)
dist = [sys.maxsize]*(n)
dist[k-1]=0
heapq.heappush(q,(0,k))
while q:
d,u = heapq.heappop(q)
for weight,v in adj[u]:
if dist[v-1]>dist[u-1]+weight:
dist[v-1]=dist[u-1]+weight
heapq.heappush(q,(dist[v-1],v))
for i in range(len(dist)):
if dist[i]==sys.maxsize:
return -1
return max(dist)
Как мы видим, время выполнения одинаковое, возможно, можно что-то улучшить, где-то оптимизировать и т.д. но время сильно не улучшится, т.к. данных не на 20 млрд операций :)
НО! Мой то алгоритм еще и с отрицательными ребрами может!
Обработка недостижимых узлов
Допустим, у нас поставлена задача найти кратчайшие пути с узла k до всех остальных узлов. При этом не гарантируется, что до каждого узла возможно достичь от k-ого. Тогда внесем в код небольшую обработку такого события. Код вычисляет все кратчайшие расстояния от каждого узла до всех ему достижимых. При попытке достичь недостижимый узел, выведется бесконечное расстояние.
Hidden text
from collections import deque
input_graph = [[1, 2, 5], [1, 3, -6],
[2, 4, 4], [2, 3, 7],
[3, 2, -2], [3, 4, 6]]
n = 4
for k in range(1, 5):
print(f'Источник - узел {k}')
arr = [[] for _ in range(n + 1)]
graph = {}
for item in input_graph:
arr[item[0]].append((item[1], item[2]))
queue = deque()
graph[k] = {}
for i in arr[k]:
neighbor = i[0]
graph[k][neighbor] = i[1]
queue.append(neighbor)
while queue:
current = queue.popleft()
if current not in graph:
graph[current] = {}
for i in arr[current]:
neighbor = i[0]
if neighbor not in graph:
graph[i[0]] = {}
queue.append(neighbor)
graph[current][neighbor] = i[1]
lst = deque([key for key in graph.keys()]) # Формируем очередность прохождения узлов графа
parents = {} # {Нода: его родитель}
costs = {} # Минимальный вес для перехода к этой ноде (кратчайшие длины пути до ноды от начального узла)
infinity = float('inf') # Бесконечность (когда минимальный вес до ноды еще неизвестен)
processed = set() # Множество обработанных нод
cycle_count = 0
while lst:
node = lst.popleft()
if node not in processed: # Если нода уже обработана не будем ее заново смотреть (иначе м.б. беск. цикл)
for child, cost in graph[node].items(): # Проходимся по всем детям
cycle_count += 1
new_cost = cost + costs.get(node,
0) # Путь до ребенка = путь родителя + вес до ребенка (если родителя нет, то путь до него = 0)
min_cost = costs.get(child,
infinity) # Смотрим на минимальный путь до ребенка (если его до этого не было, то он беск.)
if new_cost < min_cost: # Если новый путь будет меньше минимального пути до этого,
costs[child] = new_cost # то заменяем минимальный путь на вычисленный
parents[child] = node # Так же заменяем родителя, от которого достигается мин путь
if child in processed: # UPDATE: если ребенок был в числе обработанных
lst.appendleft(child) # Вновь добавляем эту ноду в список для того, чтобы обработать его заново
processed.remove(child) # Удаляем из обработанных
processed.add(node) # Когда все дети (ребра графа) обработаны, вносим ноду в множество обработанных
print(f'Количество операций: {cycle_count}')
print(f'Минимальные стоимости от источника до ноды: {costs}')
print(f'Родители нод, от которых исходит кратчайший путь до этой ноды: {parents}')
def get_shortest_path(start, end):
'''
Проходится по родителям, начиная с конечного пути,
т.е. ищет родителя конечного пути, потом родителя родителя и т.д. пока не дойдет до начала пути.
Тем самым мы строим обратную цепочку нод, которую мы инвертируем в конце, чтобы получить
истинный кратчайший путь
'''
parent = parents.get(end, 'No') # Проверяем, достижима ли нода
if parent == 'No':
return f'Кратчайший путь от {start} до {end}: узел недостижим. Расстояние бесконечно'
result = [end]
while parent != start:
result.append(parent)
parent = parents[parent]
result.append(start)
result.reverse()
result = map(str, result) # В случае если имена нод будут числами, а не строками (для дальнейшего join)
shortest_distance = costs[end]
print('-->'.join(result))
return f'Кратчайший путь от {start} до {end}: {shortest_distance}'
for i in range(1, n+1):
if i == k:
continue
print(get_shortest_path(start=k, end=i))
Выводы
Алгоритм работает! Причем с неплохой скоростью. Если учитывать то, что еще и с отрицательными весами работает - то это просто отлично! Но если в задаче указано, что нет отрицательных ребер, то нужно все-таки пользоваться Дейкстрой с кучей. Если мало данных или задача сама не знает, есть ли там отрицательные веса, то можно смело пользоваться моим (наверное, так можно уже сказать) алгоритмом.
(UPD) Меня опередили...
Спустя почти 30к просмотров материала один единственный пользователь подсказал мне, что такой алгоритм уже существовал, но им очень редко пользуются, мало кто о нем вообще знает и информации о нем гораздо меньше, хотя он является наибыстрейшим алгоритмом на сегодняшний день. Называется алгоритм Левита. Его идея в точности совпадает с моей (обходить граф в ширину и обновлять соседей поуровнево в очереди). Единственное, реализация этой идеи лежит в самом алгоритме, а не в начале. Да и на самом деле мой алгоритм тоже в самом теле цикла повторно обходил в ширину граф с помощью очереди, т.е. препроцессинг мой был по сути не нужен. Мне в голову это не приходило, но я по сути делал лишнюю работу. Но сама идея мне пришла правильная, реализация не сказать, что подвела, но можно было лучше. А нужно было лишь правильно реализовать структуру графа и правильно с ним работать. По сути, у меня вышла точная его копия, но с "лишним" препроцессингом.
На самом деле существует 2 реализации алгоритма Левита. С одной очередью и 2-мя очередями. Кому интересно, можете ознакомиться (правда информации о нем не сильно много, но все же есть). Так вот, моя версия была с одной очередью. Она в очень редких случаях будет медленнее, чем с 2-мя очередями. Но "мой" алгоритм можно легко переделать под 2 очереди, и таким образом время, не считая препроцессинга, будет одинаковым. Да по сути это и будет сам алгоритм Левита с 2-мя очередями, просто с лишними телодвижениями и другой структурой графа, в общем, слегка измененный, но суть та же. Код алгоритма:
def levit(graph: List[List[int]], n: int, k: int):
graph = [[] for _ in range(n + 1)]
for [node1, node2, w] in input_graph:
graph[node1].append((node2, w))
infinity = float('inf')
costs = [infinity] * (n + 1)
costs[k] = 0
processed = [False] * (n + 1)
unprocessed = [True] * (n + 1)
unprocessed[k] = False
nq = deque([k])
uq = deque()
cycle_count = 0
while nq or uq:
i = uq.popleft() if uq else nq.popleft()
parent_cost = costs[i]
edges = graph[i]
for (j, w) in edges:
cycle_count += 1
new_cost = parent_cost + w
if unprocessed[j]:
costs[j] = new_cost
nq.append(j)
unprocessed[j] = False
continue
if costs[j] > new_cost:
costs[j] = new_cost
if processed[j]:
uq.append(j)
processed[j] = False
processed[i] = True
return costs[1:], cycle_count
Как видим, алгоритм Левита показал себя самым быстрым среди всех. "Мой алгоритм" (Левит с одной очередью) на втором месте, без препроцессинга был бы еще быстрее. Но у этого варианта есть вероятность, что сложность при очень "противном" графе взлетит до экспоненциальной. Поэтому, лучше пользоваться с 2-мя очередями, там этой проблемы нет.
Итоги
Что ж, честно признаюсь, я сильно расстроился, когда узнал, что уже существует такой алгоритм :( Проблема в том, что он очень "не популярный". В учебных материалах ни разу не слышал об упоминании этого алгоритма. Да и вообще русскоязычный материал по этому алгоритму очень скуден. В англоязычном варианте этот алгоритм называют по-другому. Даже пользователи на этой площадке, судя по тому, что никто долго мне не говорил о нем, не знали о существовании этого алгоритма...
Таким образом, я пытался оптимизировать актуальную проблему поиска кратчайшего пути.
Первое чувство, которое меня посетило в момент знакомства с существующим алгоритмом было отчаяние... Думал, что зря проделал работу, думал, смогу сделать этот мир чуточку лучше, но все было зря. Однако, я посмотрел на это трезво и меня посетила мысль: "Ты самостоятельно пришел к самому быстрому на сегодняшний день алгоритму, да ты огонь просто!". Плюс я познакомил Вас, дорогие друзья, с этим редким алгоритмом, пользуйтесь на здоровье!
Всем спасибо, рад был пообщаться, спасибо за подсказки и попытки оптимизировать "мой" вариант алгоритма. Получил опыт, удовольствие, и, надеюсь, вы тоже. Всем добра!














